
2008. 12. 3. 20:28
@GSMC/김경환: Pattern Recognition
350p
* Lyapunov functions http://en.wikipedia.org/wiki/Lyapunov_functions
objective functions http://en.wikipedia.org/wiki/Objective_function
7.2.1 Simulated Annealing
http://en.wikipedia.org/wiki/Annealing_(metallurgy)
http://en.wikipedia.org/wiki/Simulated_annealing
successful in a wide range of energy functions or energy landscapes,
unlikely so in cases such as the "golf course landscape".
352p
7.2.2 The Boltzmann Factor
Boltzmann factor
http://en.wikipedia.org/wiki/Boltzmann_factor
partition function for a normalization constant
http://en.wikipedia.org/wiki/Partition_function_(statistical_mechanics)
http://en.wikipedia.org/wiki/Boltzmann_distribution
the # of configurations = 2^N
Fig.7.1 - Boltzmann networks is to indicate the state fo each node
: The optimization problem is to find a configuration (i.e., assignment of all s_i) that minimizes the energy.
Fig.7.2
: Simulated annealing method uses randomness, governed by a control parameter or "temperature" T.
Algorithm 1. Stochastic Simulated Annealing
7.1 Introduction
search for finding acceptable model parameters
stochastic methods relied on randomness
stochastic methods relied on randomness
(1) Boltzmann learning (from statistical mechanics in physics)
(2) genetic algorithms (from the mathematical theory of evolution in biology)
: preferable in complex problems
: high computational burden
351p
: high computational burden
351p
7.2 Stochastic Search
If we suggest an associated interaction energy of each pair of magnets,
then, to optimize the energy of the full system, we are to find the configuration of states of the magnets.
* Lyapunov functions http://en.wikipedia.org/wiki/Lyapunov_functions
objective functions http://en.wikipedia.org/wiki/Objective_function
7.2.1 Simulated Annealing
http://en.wikipedia.org/wiki/Annealing_(metallurgy)
http://en.wikipedia.org/wiki/Simulated_annealing
As the temperature is lowered, the system has increased probability of finding the optimum configuration.
successful in a wide range of energy functions or energy landscapes,
unlikely so in cases such as the "golf course landscape".
352p
7.2.2 The Boltzmann Factor
Boltzmann factor
http://en.wikipedia.org/wiki/Boltzmann_factor
partition function for a normalization constant
http://en.wikipedia.org/wiki/Partition_function_(statistical_mechanics)
http://en.wikipedia.org/wiki/Boltzmann_distribution
the # of configurations = 2^N
Fig.7.1 - Boltzmann networks is to indicate the state fo each node
: The optimization problem is to find a configuration (i.e., assignment of all s_i) that minimizes the energy.
Fig.7.2
: Simulated annealing method uses randomness, governed by a control parameter or "temperature" T.
The number of states declines exponentially with increasing energy.
Because of the statistical independence of the magnets, for large N the probability of finding the state in energy E also decays exponentially.
The dependence of the probability upon T in the Boltzmann factor:
At high T, the probability is distributed roughly evenly among all configurations, while at low T it is concetrated at the lowest-energy configurations.
In the case of large N, the number of configurations decays exponentially with the energy of the configuration.
Because of the statistical independence of the magnets, for large N the probability of finding the state in energy E also decays exponentially.
The dependence of the probability upon T in the Boltzmann factor:
At high T, the probability is distributed roughly evenly among all configurations, while at low T it is concetrated at the lowest-energy configurations.
In the case of large N, the number of configurations decays exponentially with the energy of the configuration.
> Simulated Annealing Algorithm
1) initiate randomized states & select a high initial temperature T
(in the simulation, T is a control parameter that will control the randomness)
2) choose randomly a node i with its state s_i = +1
3) calculate the system energy in this configuration
4) recalculate the energy for a candidate new state s_i = -1
5) accept this change in state if this candidate state has a lower energy, or if the energy is higher, accept this with a probability from the Boltzmann factor.
6) poll (select and test) the nodes randomly several times and set their states
7) lower the temperature and repeat the polling
8) simluated annealing terminates when the temperature is very low (near zero)
(if the cooling has been sufficiently slow, the system has a high probability of being in a low-energy state)
1) initiate randomized states & select a high initial temperature T
(in the simulation, T is a control parameter that will control the randomness)
2) choose randomly a node i with its state s_i = +1
3) calculate the system energy in this configuration
4) recalculate the energy for a candidate new state s_i = -1
5) accept this change in state if this candidate state has a lower energy, or if the energy is higher, accept this with a probability from the Boltzmann factor.
6) poll (select and test) the nodes randomly several times and set their states
7) lower the temperature and repeat the polling
8) simluated annealing terminates when the temperature is very low (near zero)
(if the cooling has been sufficiently slow, the system has a high probability of being in a low-energy state)
The occational acceptance of a state that is energetically less favorable allows the system to jump out of unacceptable local energy minima.
Algorithm 1. Stochastic Simulated Annealing
'@GSMC > 김경환: Pattern Recognition' 카테고리의 다른 글
| ch.6 Multilayer Neural Networks (0) | 2008.11.21 |
|---|---|
| ch.5 Linear Discriminant Functions (0) | 2008.11.02 |
| ch.4 Nonparametric Techniques (0) | 2008.10.21 |
| ch.3 Maximum-Likelihood and Bayesian Parameter Estimation (0) | 2008.10.08 |
| ch.2 Bayesian Decision Theory (0) | 2008.09.25 |
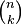 is the number of k-element subsets (the k-combinations) of an n-element set; that is, the number of ways that k things can be 'chosen' from a set of n things.
is the number of k-element subsets (the k-combinations) of an n-element set; that is, the number of ways that k things can be 'chosen' from a set of n things.