
2010. 6. 2. 23:53
Computer Vision
cvCalibrateCamera2( ) 함수는 /opencv/src/cv/cvcalibration.cpp 파일에 정의되어 있다.
또는 OpenCV – Trac 웹페이지: /branches/OPENCV_1_0/opencv/src/cv/cvcalibration.cpp
ref. Learning OpenCV: Chapter 11 Camera Models and Calibration
378p: "Calibration"
http://www.vision.caltech.edu/bouguetj/calib_doc/
1) number of views
인자 중 pointCounts – Integer 1xM or Mx1 vector (where M is the number of calibration pattern views)
그런데 우리의 경우 매 입력 프레임 한 개이므로, M = 1
2) rotation vector와 translation vector
cvCalibrateCamera2() 함수의 output 중 외부 파라미터를 받을 matrices를 다음과 같이 생성하면
아래와 같은 에러 메시지가 난다.
다음과 같이 바꾸어야 함.
3) rotation matrix
카메라 회전을 원하는 형태로 얻으려면 rotation vector를 rotation matrix로 바꾸어야 한다. (아래 설명 참조.)
check#1. 대응점 쌍 개수
cvCalibrateCamera2() 함수는 유효한 대응점 4쌍이 있으면 camera calibration을 한다고 하지만, 함수 실행 에러가 나지 않고 계산값을 내보낼 뿐 그것이 정확한 결과는 아니다. ( OpenCV의 알고리즘은 렌즈 왜곡 변수와 카메라 내부 변수를 따로 분리해서 계산하고 있다. 렌즈 왜곡 변수에 대해서는 radial distortion coefficients 3개와 tangential distortion coefficients 2개, 총 5개의 미지수의 해를 구하고자 하므로 이론상 이미지 상의 3개의 2차원 (x,y) 점으로부터 6개의 값을 얻으면 계산할 수 있다.
그런데, 우리 프로그램에서 4쌍의 대응점으로 카메라 캘리브레이션을 한 결과는 다음과 같다.
재확인...
즉, 4쌍의 대응점으로부터 카메라 매트릭스를 산술적으로 계산해 내기는 한다. 그런데 현재 패턴을 사용하여 대응점이 4쌍이 나오는 경우는 대개 패턴 중 격자 한 개의 코너점 4개가 검출된 경우이다. 그러므로 인접한 4점의 위치 좌표에 렌즈 왜곡의 효과가 충분히 반영되어 있다고 볼 수 없으므로 위의 출력 결과와 같이 k1 = 0으로 렌즈 왜곡이 없다고 보는 것과 같은 결과가 된다.
한 가지 더. cvCalibrateCam2( ) 함수가 내부적으로 시행하는 첫번째 일은 cvConvertPointsHomogeneous( ) 함수를 호출하여, input matrices로 서로 대응하는 world coordinate과 image coordinate을 각기 1차원 Homogeneous coordinate으로 변환하는 것이다. 그런데 함수 설명에 다음과 같은 내용이 있다. "It is always safe to use the function with number of points , or to use multi-channel Nx1 or 1xN arrays."
, or to use multi-channel Nx1 or 1xN arrays."
카메라 렌즈에 skew가 없다는 가정을 전제로 한다.
캘리브레이션을 위해 대응점을 얻을 패턴이 평면 (z = 0)인 경우에만 intrinsic parameter의 고정값 초기화가 가능하다. (
"where z-coordinates of the object points must be all 0’s.")
 cvcalibration.cpp
cvcalibration.cpp또는 OpenCV – Trac 웹페이지: /branches/OPENCV_1_0/opencv/src/cv/cvcalibration.cpp
ref. Learning OpenCV: Chapter 11 Camera Models and Calibration
378p: "Calibration"
http://www.vision.caltech.edu/bouguetj/calib_doc/
388p: Intrinsic parameters are directly tied to the 3D geometry (and hence the extrinsic parameters) of where the chessboard is in space; distortion parameters are tied to the 3D geometry of how the pattern of points gets distorted, so we deal with the constraints on these two classes of parameters separately.
389p: The algorithm OpenCV uses to solve for the focal lengths and offsets is based on Zhang's method [Zhang00], but OpenCV uses a different method based on Brown [Brown71] to solve for the distortion parameters.
1) number of views
인자 중 pointCounts – Integer 1xM or Mx1 vector (where M is the number of calibration pattern views)
그런데 우리의 경우 매 입력 프레임 한 개이므로, M = 1
int numView = 1; // number of calibration pattern views
// integer "1*numView" vector
CvMat* countsP = cvCreateMat( numView, 1, CV_32SC1 );
// the sum of vector elements must match the size of objectPoints and imagePoints
// cvmSet( countsP, 0, 0, numPair ); // <-- 이렇게 하면 에러 남. 아래로 변경
cvSet( countsP, cvScalar(numPair) );
// integer "1*numView" vector
CvMat* countsP = cvCreateMat( numView, 1, CV_32SC1 );
// the sum of vector elements must match the size of objectPoints and imagePoints
// cvmSet( countsP, 0, 0, numPair ); // <-- 이렇게 하면 에러 남. 아래로 변경
cvSet( countsP, cvScalar(numPair) );
2) rotation vector와 translation vector
cvCalibrateCamera2() 함수의 output 중 외부 파라미터를 받을 matrices를 다음과 같이 생성하면
// extrinsic parameters
CvMat* vectorR = cvCreateMat( 3, 1, CV_32FC1 ); // rotation vector
CvMat* vectorT = cvCreateMat( 3, 1, CV_32FC1 ); // translation vector
CvMat* vectorR = cvCreateMat( 3, 1, CV_32FC1 ); // rotation vector
CvMat* vectorT = cvCreateMat( 3, 1, CV_32FC1 ); // translation vector
아래와 같은 에러 메시지가 난다.
OpenCV ERROR: Bad argument (the output array of rotation vectors must be
3-channel 1xn or nx1 array or 1-channel nx3 or nx9 array, where n is
the number of views)
in function cvCalibrateCamera2, ../../src/cv/cvcalibration.cpp(1488)
in function cvCalibrateCamera2, ../../src/cv/cvcalibration.cpp(1488)
OpenCV ERROR: Bad argument (the output array of translation vectors must
be 3-channel 1xn or nx1 array or 1-channel nx3 array, where n is the
number of views)
in function cvCalibrateCamera2, ../../src/cv/
in function cvCalibrateCamera2, ../../src/cv/
다음과 같이 바꾸어야 함.
// extrinsic parameters
CvMat* vectorR = cvCreateMat( 1, 3, CV_32FC1 ); //
rotation vector
CvMat* vectorT = cvCreateMat( 1, 3, CV_32FC1 ); // translation vector
CvMat* vectorT = cvCreateMat( 1, 3, CV_32FC1 ); // translation vector
3) rotation matrix
카메라 회전을 원하는 형태로 얻으려면 rotation vector를 rotation matrix로 바꾸어야 한다. (아래 설명 참조.)
Learning OpenCV: 394p
"(The rotation vector) represents an axis in three-dimensional space in the camera coordinate system around which (the pattern) was rotated and where the length or magnitude of the vector encodes the counterclock-wise angle of the rotation. Each of these rotation vectors can be converted to a 3-by-3 rotation matrix by calling cvRodrigues2()."
check#1. 대응점 쌍 개수
cvCalibrateCamera2() 함수는 유효한 대응점 4쌍이 있으면 camera calibration을 한다고 하지만, 함수 실행 에러가 나지 않고 계산값을 내보낼 뿐 그것이 정확한 결과는 아니다. ( OpenCV의 알고리즘은 렌즈 왜곡 변수와 카메라 내부 변수를 따로 분리해서 계산하고 있다. 렌즈 왜곡 변수에 대해서는 radial distortion coefficients 3개와 tangential distortion coefficients 2개, 총 5개의 미지수의 해를 구하고자 하므로 이론상 이미지 상의 3개의 2차원 (x,y) 점으로부터 6개의 값을 얻으면 계산할 수 있다.
그런데, 우리 프로그램에서 4쌍의 대응점으로 카메라 캘리브레이션을 한 결과는 다음과 같다.

대응점 4쌍으로 패턴 인식에 성공한 경우 |

왼쪽 영상에 보이는 대응점 4쌍으로 카메라 캘리브레이션한 결과를 가지고 다시 패턴의 4점을 입력 영상 위에 리프로젝션하여 확인 |
frame # 103 ---------------------------
# of found lines = 5 vertical, 5 horizontal
vertical lines:
horizontal lines:
p.size = 25
CRimage.size = 25
# of corresponding pairs = 4 = 4
camera matrix
fx=1958.64 0 cx=160.37
0 fy=792.763 cy=121.702
0 0 1
lens distortion
k1 = -8.17823
k2 = -0.108369
p1 = -0.388965
p2 = -0.169033
rotation vector
4.77319 63.4612 0.300428
translation vector
-130.812 -137.452 714.396
# of found lines = 5 vertical, 5 horizontal
vertical lines:
horizontal lines:
p.size = 25
CRimage.size = 25
# of corresponding pairs = 4 = 4
camera matrix
fx=1958.64 0 cx=160.37
0 fy=792.763 cy=121.702
0 0 1
lens distortion
k1 = -8.17823
k2 = -0.108369
p1 = -0.388965
p2 = -0.169033
rotation vector
4.77319 63.4612 0.300428
translation vector
-130.812 -137.452 714.396
재확인...

대응점 4쌍으로 패턴 인식에 성공한 경우 |

왼쪽 영상에 보이는 대응점 4쌍으로 카메라 캘리브레이션한 결과를 가지고 다시 패턴의 4점을 입력 영상 위에 리프로젝션하여 확인 |
frame # 87 ---------------------------
# of found lines = 5 vertical, 5 horizontal
vertical lines:
horizontal lines:
p.size = 25
CRimage.size = 25
# of corresponding pairs = 4 = 4
camera matrix
fx=372.747 0 cx=159.5
0 fy=299.305 cy=119.5
0 0 1
lens distortion
k1 = -7.36674e-14
k2 = 8.34645e-14
p1 = -9.57187e-15
p2 = -4.6854e-15
rotation vector
-0.276568 -0.125119 -0.038675
translation vector
-196.841 -138.012 168.806
# of found lines = 5 vertical, 5 horizontal
vertical lines:
horizontal lines:
p.size = 25
CRimage.size = 25
# of corresponding pairs = 4 = 4
camera matrix
fx=372.747 0 cx=159.5
0 fy=299.305 cy=119.5
0 0 1
lens distortion
k1 = -7.36674e-14
k2 = 8.34645e-14
p1 = -9.57187e-15
p2 = -4.6854e-15
rotation vector
-0.276568 -0.125119 -0.038675
translation vector
-196.841 -138.012 168.806
즉, 4쌍의 대응점으로부터 카메라 매트릭스를 산술적으로 계산해 내기는 한다. 그런데 현재 패턴을 사용하여 대응점이 4쌍이 나오는 경우는 대개 패턴 중 격자 한 개의 코너점 4개가 검출된 경우이다. 그러므로 인접한 4점의 위치 좌표에 렌즈 왜곡의 효과가 충분히 반영되어 있다고 볼 수 없으므로 위의 출력 결과와 같이 k1 = 0으로 렌즈 왜곡이 없다고 보는 것과 같은 결과가 된다.
한 가지 더. cvCalibrateCam2( ) 함수가 내부적으로 시행하는 첫번째 일은 cvConvertPointsHomogeneous( ) 함수를 호출하여, input matrices로 서로 대응하는 world coordinate과 image coordinate을 각기 1차원 Homogeneous coordinate으로 변환하는 것이다. 그런데 함수 설명에 다음과 같은 내용이 있다. "It is always safe to use the function with number of points
, or to use multi-channel Nx1 or 1xN arrays." 카메라 렌즈에 skew가 없다는 가정을 전제로 한다.
캘리브레이션을 위해 대응점을 얻을 패턴이 평면 (z = 0)인 경우에만 intrinsic parameter의 고정값 초기화가 가능하다. (
"where z-coordinates of the object points must be all 0’s.")
'Computer Vision' 카테고리의 다른 글
| Xiaochun Cao & Hassan Foroosh "CAMERA CALIBRATION WITHOUT METRIC INFORMATION USING 1D OBJECTS" (0) | 2010.06.08 |
|---|---|
| OpenCV: cvFindCornerSubPix() (0) | 2010.06.04 |
| Duane C. Brown "Close-Range Camera Calibration" (0) | 2010.06.02 |
| test: composing OpenCV Iplimage and OpenGL graphics in one window screen (0) | 2010.05.30 |
| virtual studio 구현: virtual object rendering test (0) | 2010.05.27 |























 swPark_2000rtim.pdf
swPark_2000rtim.pdf



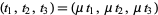
 .
.










