less.. (본문 닫기) 프로그래밍 언어 개론
출처 : HYPERLINK "http://www.e-campus.co.kr" http://www.e-campus.co.kr
프로그래밍 언어는 말 그대로 프로그램을 작성하는데 쓰이는 언어로서, 우리가 컴퓨터에게 무엇인가를 하기를 원하는 작업을 언어로써 체계적으로 표기하는 것 입니다. 예를 들어, 키보드로 입력한 숫자나 문자를 읽어 들이거나 사칙연산을 하거나, 혹은 프로그램의 결과물을 모니터나 프린터로 출력하는 등의 작업을 프로그래밍 언어를 사용하여 컴퓨터에게 명령할 수 있습니다. 지금 이 강좌를 보기 위해 키보드로 문자를 입력하고 마우스를 클릭하는 것도 하나의 명령입니다. 이러한 명령들은 모두 프로그래밍 언어로 짜여졌으며, 다만 여러분은 이미 짜여진 프로그램을 사용하는 것입니다. 프로그래밍 언어로 도대체 어떻게 이렇게 멋진 프로그램을 만들 수 있을까 하는 궁금증이 생기셨을지도 모르겠습니다.
여러분은 이 강좌에서 프로그래밍 언어의 일반적인 지식을 배우게 됩니다. 이 강좌를 배웠다고 해서 당장 프로그램을 짤 수 있는 것은 아닙니다. 진짜 프로그램을 짤 수 있는 것은 프로그래밍 언어 그 자체입니다. 흔히 말하는 C/C++ 언어, JAVA 언어 같은 것 말입니다. 본 강좌에서는 이러한 프로그래밍 언어의 전반에 대하여 학습하도록 하겠습니다.
프로그래밍 언어들이 제공하는 일반적인 특성 또는 고유의 구조나 특징들을 이해함으로써 특정 프로그램을 짜기 위해 필요한 적절한 언어를 선택할 수 있습니다.
프로그래밍 언어들이 갖고 있는 공통적인 특성을 파악하여 새로운 프로그래밍 언어를 쉽게 배울 수 있습니다.
강좌는 초보자를 위한 강좌이지만, 하나 이상의 프로그래밍 언어를 미리 접해본 분들에게 적극 권장합니다. 그러나 혹시 이 강좌를 통해 프로그래밍 언어를 처음 접해보는 분이라 해도 강좌 자체가 초보자용이기 때문에 미리 겁내실 필요는 없으며, 다만 C/C++ 나 PASCAL 같은 프로그래밍 언어 책을 옆에 끼고 수강하시면 훨씬 나은 학습 효과가 기대되리라 생각합니다.
, 이제 프로그래밍 언어 과정에 대해 아시겠죠?
이번에는 왼쪽의 메뉴바에서 학습구성을 눌러 본 과정에서 학습할 내용에 대해 살펴 보세요.
학습자님은 프로그래밍 언어 과정을 통해 프로그래밍 언어에 대한 대략적인 내용과 함께 구문, 변수, 자료형, 수식과 할당문, 제어구조, 부프로그래밍, 추상 자료형, 예외 처리, 객체지향형 프로그래밍 등에 대해 배우겠습니다.
학습내용은 다음과 같이 총 10 장으로 구성됩니다.
1 장 프로그래밍 언어 기초 이번 장에서는
1 절 프로그래밍 언어란 무엇인가?
2 절 프로그래밍 언어의 평가기준
3 절 컴파일러 언어와 인터프리터 언어
4 절 주요 프로그래밍 언어
2 장 구문 정의와 구문 표현 이번 장에서는
1 절 구문 소개
2 절 구문 표현 방법
3 장 변수 이번 장에서는
1 절 변수 기초
2 절 바인딩
3절 형 검사
4 절 변수의 실효 범위와 초기화
4 장 자료형 이번 장에서는
1 절 기본 자료형
2 절 문자열
3 절 배열형
4 절 레코드형
5 절 유니언형
6 절 집합형
7 절 포인터형
5 장 수식과 할당문 이번 장에서는
1절 수식
2 절 할당문
6 장 제어구조 이번 장에서는
1 절 복합문
2 절 선택문
3 절 반복문
7 장 부프로그램 이번 장에서는
1 절 부프로그램의 소개
2 절 매개변수 전달기법
3 절 부프로그램의 기억 장소 할당
4 절 부프로그램의 부가적 기능들
8 장 추상 자료형 이번 장에서는
1 절 추상화의 개념
2 절 캡슐화의 개념
3 절 추상 자료형의 소개
4절 C++의 'CLASS'
9 장 예외 처리 이번 장에서는
1 절 예외 처리
2절 C++의 예외 처리
10 장 객체지향형 프로그래밍 이번 장에서는
1 절 객체지향형 프로그래밍 소개
2 절 객체지향형 프로그래밍의 구성 요소
3 절 C++ 에서의 객체지향형 프로그래밍
, 본 과정의 학습내용이 어떻게 구성되어 있는지 아시겠죠?
이번에는 왼쪽의 메뉴바에서 사용법을 클릭하여 학습진행 방법 및 학습보조 버튼의 사용법을 살펴 보세요.
제1 장 프로그래밍 언어 기초
안녕하세요!
이 장에서는 프로그래밍 언어에 대한 본격적인 학습을 시작하기 전에 프로그래밍 언어의 의의를 살펴보려고 합니다. 또한 프로그래밍 언어의 평가 기준과 구현 방법에 관해서도 간단히 살펴보고, 구체적인 프로그래밍 언어를 하나하나 짚어가면서 대략적인 특징들을 살펴보도록 하겠습니다.
< 학습목표 >
- 프로그래밍 언어의 의미를 이해할 수 있습니다.
- 프로그래밍 언어를 평가하고 적절한 프로그래밍 언어를 선택할 수 있습니다.
- 컴파일러 언어와 인터프리터 언어의 특징을 이해할 수 있습니다.
< 학습내용 >
- 프로그래밍 언어란 무엇인가?
- 프로그래밍 언어의 평가기준
- 컴파일러 언어와 인터프리터 언어
- 주요 프로그래밍 언어
1. 프로그래밍 언어란 무엇인가 ?
(1) 프로그래밍 언어
이 강좌 안내에 나와 있는 바와 같이, 프로그래밍 언어란 프로그램을 작성하는데 쓰이는 언어로서, 우리가 컴퓨터에게 무엇인가를 하기를 원하는 작업을 언어로써 체계적으로 표기하는 것입니다.
우리가 쓰고 있는 한글이나 다른 모든 나라의 언어들은 고급 언어입니다. 사람의 생각과 감정을 자유자재로 표현할 수 있기 때문입니다. 그러나 컴퓨터는 매우 지능이 낮은 기계입니다. 우리들이 일상적으로 사용하는 언어들을 알아 듣는다는 것은 매우 사치스러운 일이지요. 실제로 컴퓨터가 알아들을 수 있는 언어는 사실 언어가 아닙니다. 0 과 1 이라는 숫자로 조합된 하나의 기호체계 입니다. 이것을 기계어라고 합니다. 이러한 기계어를 일일이 조합하는 일은 매우 어려울 뿐더러, 기계어를 가지고 요즘 같은 복잡한 프로그램을 짠다는 것은 매우 불가능한 일입니다. 그래서, 사용자가 보다 친숙한 언어, 즉 일상적으로 사용하는 언어와 비슷한 언어를 가지고 프로그램을 짤 수 있게 하도록 한 것이 프로그래밍 언어입니다.
그렇다면, 컴퓨터가 이 언어들을 어떻게 알아들을 수 있을까 하는 의문이 생기셨을 것으로 생각됩니다. 그 점은 여러분이 전혀 걱정하실 일이 아닙니다. 왜냐하면 프로그래밍 언어마다 여러분이 짠 프로그램을 기계어로 번역해 주는 고유의 번역기가 있으니까요. 이 부분에 대해서는 1.3 절에서 다시 언급하도록 하겠습니다.
(2) 프로그래밍 언어를 배우는 이유
프로그래밍 언어를 배우는 것에는 어떤 의미가 있을까요? 간단하게 한번 살펴 봅시다.
- 자신의 아이디어를 프로그래밍 언어로 표현할 수 있는 능력을 길러 줍니다.
- 특정 프로그램에 적합한 프로그래밍 언어를 선택할 수 있는 지식을 갖게 해 줍니다.
- 새로운 언어를 쉽게 배울 수 있습니다.
- 여러 프로그래밍 언어들이 제공하는 다양한 구조나 특징들을 이해함으로써 적절한 구조를 선택, 구현할 수 있게 하여 보다 좋은 프로그램을 설계할 수 있습니다.
- 프로그래밍 언어의 개념을 잘 적용시킴으로써 컴퓨팅에 관한 시야가 넓어집니다.
(3) 프로그래밍 영역
프로그래밍 언어마다 각 영역에서 쓰이는 용도가 다릅니다.
각 영역에서 어떤 프로그래밍 언어가 쓰이는지 예를 들어보겠습니다.
영역 프로그래밍 언어
플랫과학기술 (수치계산용 ) FORTRAN, ALGOL60
비지니스용 COBOL
인공지능용 LISP, PROLOG
시스템 프로그래밍용 PL/S, BLISS, ALGOL, C/C++
특수 목적용 GPSS (시뮬레이션을 위한 언어 )
2. 프로그래밍언어의 평가 기준
어느 프로그래밍 언어건 간에 완벽함을 갖춘 언어는 드뭅니다. 그래서 프로그래밍 언어를 평가하는 기준이 있고, 이러한 기준에 따라 자신의 프로그램에 가장 적합한 프로그래밍 언어를 찾는 것입니다. 이제부터 프로그래밍 언어를 어떤 기준으로 평가하는지 알아봅시다.
(1) 읽기 쉬움 (Readability)
단순성 :
프로그램 내의 구문 자체가 복잡하지 않고 기본 골격이 너무 크면 안됩니다.
직교성 :
프로그래밍 언어의 기본적인 기능과 특성이 각각 별도로 이해 가능해야 합니다. 즉, 여러 기능이 얽히면 안되고 그들이 조합됐을 때, 상호간의 작용이 자유로워야 합니다.
문법고려사항 :
사용자 정의 형식, 키워드, 예약어 등이 잘 정리되어 있어야 하고, 문법의 형식과 의미가 잘 맞아야 합니다.
(2) 쓰기 쉬움
프로그램을 작성하는데 있어, 프로그래밍 언어가 얼마나 쉽게 사용될 수 있는가에 대한 정도를 가리킵니다. 앞서 언급한 프로그래밍 영역에 따라 선택되어지는 언어가 달라집니다. 다음은 쓰기 쉬움에 영향을 주는 요소입니다.
단순성과 직교성 :
읽기 쉬움에서의 내용과 같습니다.
추상성 :
세부사항에 대하여 알 필요 없이 복잡한 구조나 연산을 정의하고 사용하는 것입니다.
표현성 :
얼마나 자연스럽게 문제 해결 전략을 프로그램 구조로 나타낼 수 있는지에 대한 척도입니다.
(3) 신뢰성 (Reliability)
프로그램이 모든 조건 하에서 에러 없이 자신의 명시사항을 수행하는 것을 말합니다. 다음은 프로그램의 신뢰성에 영향을 주는 몇 가지 언어의 특징들을 나열한 것입니다.
타입 체킹 :
예외 처리 :
Aliasing :
쉬움과 쓰기 쉬움 :
신뢰성에 영향을 주는 요인에 관한 본격적인 내용은 나중에 구체적으로 배울 예정이므로, 여기서는 설명을 생략하도록 하겠습니다.
3. 컴파일언어와 인터프리터 언어
앞에서 잠시 ' 프로그래밍 언어로 짠 프로그램을 컴퓨터가 어떻게 알아듣고 실행할 수 있을까' 에 대한 언급이 있었죠? 그 때, 여러분이 짠 프로그램을 기계어로 번역해 주는 번역기가 있다고 했었습니다.
그것이 바로 컴파일러와 인터프리터라는 것입니다 . 컴파일러와 인터프리터는 각각 여러분이 짠 프로그램을 기계어로 번역하여 실행할 수 있게 해주는 것입니다 .
그러나 컴파일러와 인터프리터는 다른 방식으로 프로그램을 실행합니다.
이제 컴파일러와 인터프리터에 대한 내용을 배우겠습니다.
내용을 습득하신 후에는 두 번역기의 차이점을 중심으로 기억하시기 바랍니다.
(1) 컴파일러 (Compiler) 언어
컴파일이란, 한 언어를 동등한 의미를 갖는 다른 언어로 바꾸는 것을 의미합니다 . 컴파일러에 의해 고급 언어를 저급 언어인 기계어로 번역하여 객체 모듈(Object Module) 을 만들고, 이 모듈을 링크, 로드하여 실행시키는 것입니다 . 컴파일러 언어에는 FORTRAN, PASCAL, C/C++ 등이 있습니다 .
다음 그림은 컴파일 과정을 나타낸 것입니다. 그림의 화살표 방향을 따라 가면 컴파일의 의미를 보다 잘 이해하실 수 있습니다.
[ 컴파일러 수행 과정]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/01/img/pl01_10_g01.gif" \* MERGEFORMATINET
컴파일러 언어의 장점
- 번역된 목적 코드 (Object Code) 저장이 가능합니다 .
- 컴파일한 후에는 그대로 재실행이 가능하므로 재사용하는 프로그램인 경우, 한번 컴파일한 후에는 다시 빠르게 실행할 수 있으므로 실행시간이 오히려 빨라질 수 있습니다.
컴파일러 언어의 단점
- 변환하는데 많은 시간이 소요됩니다.
- 줄의 원시 프로그램이 때로는 몇 백 줄의 기계어로 번역되므로 메모리 낭비가 발생할 수 있습니다
(2) 인터프리터 (Interpreter) 언어
인터프리터는 컴파일과는 다르게 중간과정 없이 원시 프로그램을 직접 저급 언어로 바꾸면서 동시에 실행하는 것입니다. 번역 과정에 있어, 고급 언어를 중간 코드까지만 번역해 그것을 소프트웨어 인터프리터로 실행하는 것입니다. 이 때, 기계어 프로그램이 만들어지는 것이 아니라, 각 중간 코드의 기능에 해당되는 서브루틴을 호출하면서 수행이 이루어지는 것입니다 . 인터프리터 언어에는 LISP, PROLOG 등이 있습니다 .
다음 그림은 인터프리트 과정을 나타낸 것입니다. 컴파일러 수행과정과 비교해 볼 때, 무척 간단한 것을 보실 수 있을 것입니다.
[ 인터파일러 수행 과정]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/01/img/pl01_12_g01.gif" \* MERGEFORMATINET
인터프리터 언어의 장점
- 실행을 위해 완전한 기계어 번역을 기다리지 않고 필요시 그 때 그 때 실행되므로 대화
식 프로그램에 좋습니다.
- 프로그램이 실행될 때까지 원시 원어 형태를 유지하므로 기억 장소가 많이 필요하지 않습니다.
인터프리터 언어의 단점
- 재실행 시 매번 원시 프로그램을 디코딩(Decoding) 하고 처리해야 하므로 시간이 많이 걸립니다.
4. 주요프로그래밍언어
이 절에서는 주요 프로그래밍 언어에 대한 간략한 특징들을 살펴보고자 합니다.
여기서 다루는 내용들은 가볍게 읽고 넘어가시면 됩니다.
FORTRAN
FORTRAN 은 최초의 고급 프로그래밍 언어로, 미국 IBM 에서 J.Backus 등에 의해 개발된 것으로서, 과학과 공학 등의 분야에서 널리 사용되고 있습니다.
ALGOL 60
ALGOL 60 은 국제 표준 기구인 ALGOL 위원회에서 제정된 언어로서, 최초로 정연한 언어이론을 바탕으로 만들어진 언어입니다. 문법 구조가 BNF 에 의해 기술된 최초의 언어이며, 수치 계산용으로 쓰입니다.
COBOL
COBOL 은 상업적 자료처리를 위해 만들어진 언어로서, 많은 양의 자료 처리와 간단한 계산 수행을 할 수 있고, 언어의 문법 구조가 영어 구문과 비슷하여 프로그램을 이해하기 쉽습니다.
BASIC
BASIC 은 시분할(Time sharing) 의 시초 언어로서, 배우기 쉽고 매우 적은 메모리양만으로도 프로그램 구현이 가능하기 때문에 초기 마이크로 컴퓨터 시대에 프로그래머들로부터 많은 인기를 얻었던 언어입니다.
PASCAL
PASCAL 은 프로그래밍 교육용 언어로서, 프로그래밍 언어의 문법 구조가 다양하고 이해하기 쉽습니다.
C/C++
C 는 벨 연구소에서 운영체제를 디자인 하는 가운데 탄생한 언어로, 프로그래머 지향적 언어입니다. 프로그램 설계가 체계적이고 이식성이 좋으며 강력함과 유연성을 갖춘 언어입니다. C++ 는 C 언어를 객체 지향형 프로그래밍 (Object-Oriented Programming) 에 접목시킨 언어 로서 기존 C 가 갖고 있는 특징을 기반으로 하고 있습니다.
LISP
LISP 은 최초의 함수형 프로그래밍 언어로서, 리스트(List) 처리 및 인공지능 분야의 연구와 구현에 널리 이용되고 있습니다.
ADA
ADA 는 매우 강력한 범용 언어로서, 군사용 내장 시스템을 위하여 병렬 처리, 예외 처리, 프로그램의 유지 보수 능력 제고에 역점을 두고 만든 언어입니다.
< 정리해봅시다 >
제 1 장 프로그래밍 언어 기초를 모두 배우셨습니다.
이 단원에서 배운 내용을 간단히 요약해 봅시다.
프로그래밍 언어는 프로그램을 작성하는데 쓰이는 언어입니다. 프로그래밍 언어에 대한 전반적인 내용을 배우게 되면, 실제 프로그램 작성하는 데 있어서
프로그래밍 영역에 따라 적절한 프로그래밍 언어를 선택할 수 있는 능력을 길러줍니다.
언어를 선택할 때에는, 각 프로그래밍 언어가 갖고 있는 고유의 특성과 프로그래밍 언어의 평가 기준을 고려해야 합니다.
언어로 프로그램을 작성한 후 컴퓨터로 실행시킬 때에는 컴퓨터가 알아들을 수 있는 기계어로의 변환이 필요한데, 이렇게 프로그램을 기계어로
번역해 주는 것이 컴파일러와 인터프리터입니다. 컴파일러는 원시 프로그램을 다단계의 코드화를 통해 기계어로 번역하는 반면 인터프리터는 바로 기계어로 번역합니다.
< 연습문제 >
1. 프로그래밍 언어란 무엇인지 간단히 설명해 보세오.
프로그래밍 언어란 프로그램을 작성하는데 쓰이는 언어로서, 우리가 컴퓨터에게 무엇인가를 하기를 원하는 작업을 언어로써 체계적으로 표기하는 것입니다.
2. 프로그래밍 언어의 평가 기준 세 가지는 무엇입니까?
읽기 쉬움, 쓰기 쉬움, 신뢰성
3. 컴파일러 언어와 인터프리터 언어의 가장 큰 차이점은 무엇일까요?
컴파일러 언어는 다단계의 구문 분석 및 코드 생성기를 이용하여 원시 프로그램을 기계어로 번역하는 반면, 인터프리터는 이러한 중간 과정 없이 코드를 한 줄 한 줄 읽어 내려가면서 곧바로 기계어로 번역합니다.
제2 장 구문정의와 구문표현
전 세계 인류들이 사용하는 언어는 그 언어 고유의 문법 체계가 있습니다. 주어와 서술어, 목적어가 있는 문장의 예를 들어 봅시다.
한국어는 " 나는 프로그래밍 언어를 공부합니다" 라는 주어+ 목적어+ 서술어의 어순으로 이루어져 있는 반면, 영어는 "I Study Programming language" 라는, 주어+ 서술어+ 목적어의 어순으로 이루어져 있습니다.
마찬가지로, 컴퓨터 프로그래밍 언어도 그 나름대로의 문법 체계를 갖고 있습니다.
이 장에서는 프로그래밍 언어의 일반적인 문법 체계를 소개하고 이해하려고 합니다. 프로그래밍 언어의 문법 체계는 일반 언어의 문법 체계처럼 정교하거나 복잡하지는 않습니다. 그러나 프로그래밍 언어는 매우 고집스러워서, 자신이 정의한 문법이 아니면 절대 받아들이지 않을 뿐더러, 컴퓨터는 어린 아이와 같아서 사용자가 문법 하나하나를 일일이 지적해주지 않으면 우왕좌왕 하게 됩니다.
따라서 이 장에서 배우는 내용이 적은 양일지라도 프로그래밍 언어의 전체적인 문법 구조를 완전하게 이해하려는 자세가 필요합니다.
< 학습목표 >
- 프로그래밍 언어의 문법 체계와 구조를 설명할 수 있습니다.
- 프로그래밍 언어를 이용하여 체계적으로 프로그램을 구성할 수 있는 기초 지식을 얻을 수 있습니다.
< 학습내용 >
- 구문 소개
- 구문 표현 방법
1. 구문소개
구문 (Syntax)과 의미 (Semantics)
프로그램은 여러 문장들로 이루어져 있고 이러한 문장은 여러 개의 단어들로 이루어져 있습니다. 이러한 단어들은 어떤 일정한 규칙에 의해서 문장으로 표현되는데, 이러한 규칙을 구문 혹은 문법이라고 합니다. 문법에는 프로그래밍 언어의 수식(Expressions), 문(Statement), 그리고 프로그램 단일체(unit) 의 형태 등이 포함됩니다.
또한 프로그래밍 문법이 나타내고 있는 뜻을 의미라고 합니다.
다음은 C 언어의 if 문장입니다. 다음을 예로 하여 문법과 의미의 차이를 이해해 봅시다.
if(<expr>) <statement>
위의 식 자체가 문법입니다. 위의 식이 내포하고 있는 뜻은 <expr> 의 현재 값이 참이면, <statement> 를 수행하라는 것입니다. 이것이 의미입니다.
프로그래밍 언어의 문법과 의미에 대해서 기본적으로 이해하셨으리라고 생각됩니다. 다음 절부터는 좀 더 구체적이고 깊이 있는 구문 체계에 대해 알아보겠습니다.
2. 구문표현의 방법
(1) BNF(Backus-Naur Forum)
BNF는 1950년대 후반 John Nackus 와 Noam Chomsky에 의해 소개된 문법 표현 방법으로 , 프로그래밍 언어를 구조적으로 표기하는 방법이며 , 문법 구조를 나타내는 메타 언어 (Meta Language)입니다 .
다음 예제는 정수를 표현하는 BNF 입니다.
<integer>→ <sign><digit-sequence>|<digit-sequence>
<sign>→ +|-
<digit-sequence>→ <digit><digit-sequence>|<digit>
<digit>→ 1|2|3|4|5|6|7|8|9|0
위 예제에서, '<', '>', ' →', '|' 은 언어의 사양을 표현하는데 사용된 기호입니다. 예를 들어, ' →' 은 ' 다음과 같이 정의된다' 라는 것을 의미하고 '|' 은 ' 혹은(or)' 을 의미합니다. 꺽쇠 괄호에 표현된 것들은 비종단 기호(Non-Terminal Symbol) 라고 하고, 문장의 추상적인 구조를 나타냅니다.
이러한 비종단 기호는 식의 왼편과 오른편에 자유롭게 나타날 수 있으며, 최종적으로 '+', '-', '1~0' 같은 종단 기호(Terminal Symbol) 로 표현될 수 있습니다. 종단 기호는 식의 오른편에만 나타나며, 실제적으로 식을 구성하는 요소입니다. 이를 테면 위의 규칙에 의해 다음과 같이 정수를 나타낼 수 있습니다.
'3', '123', '-123', '+123'
(2) EBNF(Extended Backus-Naur Form)
EBNF는 확장된 BNF로 , BNF에
선택 (Option)을 의미하는 대괄호 (Braces)
반복을 의미하는 중괄호 (Brackets)
다중 선택 사양을 의미하는 소괄호 (Parentheses)
를 추가한 것입니다. 또한
1 이상의 반복을 의미하는 '+'
0 이상의 반복을 의미하는 '*'
기호( 지수형태로 나타납니다) 가 추가되었습니다.
앞서 배운 예제를 EBNF 로 나타내어 보겠습니다. EBNF 로 표현할 수 있는 방법은 여러 가지가 있습니다. 따라서, 다음의 예가 반드시 정답은 아님을 유의하시기 바랍니다. 제가 바꿔 놓은 부분을 굵게 표시하였습니다. 아래 예에는 EBNF 로 바꿀 수 있는 부분이 더 있습니다. 여러분께서 직접 바꿔 보고 확인하시기 바랍니다.
<integer>→ <sign><digit-sequence>|<digit-sequence>
<sign>→ +|-
<digit-sequence>→ {digit}+
<digit>→ 1|2|3|4|5|6|7|8|9|0
또다른 예시보기
① <integer>→ [<sign>]<digit-sequence>
② <integer>→ [(+|-)] <digit-sequence>
③ <integer>→ [<sign>]{<digit>}+
④ <integer>→ [(+|-)]{<digit>}+
(3) 파싱과 파스트리
파스(parse)' 라는 단어가 갖고 있는 사전적 의미는, '( 문장, 어구의) 품사 및 문법적 관계를 설명하다, ( 문장을) 해부[ 분석] 하다' 입니다. 이와 같이, 프로그램을 구성하고 있는 문장들의 문법적으로 맞는 것인지 아닌지를 분석하는 과정을 ' 파싱(Parsing)' 이라고 합니다. 또한, 파싱 과정을 트리 구조를 이용하여 표현한 것을 ' 파스트리(Parse Tree)' 라고 합니다.
이제 아래의 단문을 BNF 와 파스트리로 표현하여 봅시다.
A := B * (A + C)
BNF 표현법
<assign>→ <id>:= <expr>
<id>→ A | B | C
<expr>→ <id>+ <expr>
|<id> * <expr>
|(<expr>)
|<id>
BNF 표현법에 의해서 단문을 표현하면 다음과 같이 됩니다.
<assign>⇒ <id>:= <expr>
→ A := <expr>
→ A := <id> * <expr>
→ A := B * <expr>
→ A := B * (<expr>)
→ A := B * (<id>+ <expr>)
→ A := B * ( A + <expr> )
→ A := B * ( A + <id>)
→ A := B * ( A + C )
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_06_g01.gif" \* MERGEFORMATINET
(4) 모호성 (Ambiguity)
같은 문법에 대하여 파스트리가 두 개 이상 생성되면 모호하다(ambiguous) 고 합니다. 다시 말해서, 모호하지 않은 문법의 파스트리는 오직 하나만 존재하는 것입니다. 특히, 연산자의 우선순위가 고려되어야 하는 경우에는 모호성이 있어서는 안됩니다.
다음은 모호한 문법에 대한 예제입니다.
A := B + C * A
위의 식은 B 와 C 를 먼저 더하고 A 를 곱하는가, 아니면 C 와 A 를 곱하고 B 를 더하는가에 따라 결과가 달라집니다. 따라서, 이를 나타내는 파스트리는 두 개가 존재하게 됩니다.
- 파스트리 (1)
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_07_g01.gif" \* MERGEFORMATINET
모호성과 관련한 일반적인 규칙들
연산자 결합도 (Associativity of Operator)
프로그래밍 언어 대부분이 좌결합이지만, 지수승(Exponentiation) 은 우결합입니다.
예를 들어 보겠습니다.
A := A + B + C
위의 예는 왼쪽부터 차례로 더합니다.
그렇지만 아래의 예는 오른쪽부터 계산합니다.
( 프로그래밍 언어에서 지수승 연산자는 보통 '**' 로 표현합니다.)
A := A ** B ** C
if-then-else문
if-then-else문이 중첩되게 되면 , if와 else간에 모호성이 나타나게 됩니다 .
예를 들어봅시다.
if(<expr>) then <statement>
if(<expr>) then <statement>
else <statement>
여기에서 else 가 첫 문장에 있는 if 와 한 쌍인지, 둘째 문장에 있는 if 와 한 쌍인지 모호합니다.
이러한 경우에는 통상적으로 else 에 가장 가까운 if 와 한 쌍인 것으로 봅니다.
(5) 구문도 (Syntax Graph)
고등학교 수학 교과 과정에 순서도라는 것이 있습니다. 순서도는 알고리즘을 그림으로 표현한 것 입니다. 이와 마찬가지로, BNF 와 동일하게 문장의 구문을 표현하는 방법으로 구문도라는 것이 있습니다. BNF 에서 정의된 규칙 등을 이용하여 구문도를 만들 수 있습니다.
비종단 기호는 사각형으로 표현하고 종단 기호는 원이나 타원으로 표현합니다. 그리고, 이러한 원이나 사각형은 화살표로 연결이 됩니다.
앞서 BNF 와 EBNF 로 표현하였던 정수를 구문도로 표현해 보겠습니다.
[ 기호 없는 정수형]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_09_g01.gif" \* MERGEFORMATINET
[ 기호 있는 정수형]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_09_g02.gif" \* MERGEFORMATINET
그 밖에 변수 선언과 if-then-else 문장을 다음과 같은 구문도로 표현할 수 있습니다.
[변수 선언 ]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_09_g03.gif" \* MERGEFORMATINET
[ if-then-else문 ]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_09_g04.gif" \* MERGEFORMATINET
< 정리해봅시다 >
제 2 장 구문 정의와 구문 표현을 모두 배우셨습니다. 이 단원에서 배운 내용을 간단히 요약해 봅시다.
언어를 이용하여 프로그램을 작성할 때에는 프로그래밍 언어 고유의 구문 혹은 문법을 이용합니다.
표현하는 방법에는 여러 가지가 있으나, 그 중 대표적인 것으로 BNF, EBNF, 파스트리 그리고 구문도가 있습니다.
구문을 표현할 때에는 프로그래밍 언어가 갖고 있는 본래의 의미를 정확하게 표현할 수 있도록 모호성이 없어야 합니다.
< 연습문제 >
다음과 같은 문법을 살펴봅시다.
<S>→ <A> a <B> b
<A>→ <A> b | b
<B>→ a<B> | a
1. 다음 문장 중 위의 문법으로 표현될 수 있는 것은 무엇입니까?
① baab
② bbbab
③ bbaaaaa
④ bbaab
답은 ① 입니다.
<S>→ <A> a <B> b
→ b a <B> b
→ b a a b
2. 위의 문제의 답을 유도하는 파스트리를 그려보십시오.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/02/img/pl02_11_g01.gif" \* MERGEFORMATINET
제3 장 변수
학창 시절 배운 방정식이나 함수에 대한 기억을 떠올려 봅시다. 방정식이나 함수 모두 구하고자 하는 값을 도출하기 위해 특정한 변수를 사용합니다. 예를 들면 다음과 같은 식 에서 변수 x 의 값에 따라 원하는 함수값을 얻을 수 있습니다.
f(x) = x² + 2x -3
프로그래밍 언어에서 변수를 이용하면 똑같은 프로그래밍 작업 시, 변수의 값에 따라 원하는 결과물을 얻을 수 있습니다.
변수는 프로그램에 있어 중요한 요소입니다.
다시 말해 프로그래밍 작업의 주체인 셈입니다. 이 장에서는 이러한 변수에 대한 기초적이고 일반적인 사항에 대해 알아보려고 합니다.
그리고 여러분에게 당부 드리고 싶은 말씀은, 프로그래밍 언어의 본격적인 내용에 해당하는 이번 장부터는 보다 세심한 학습 자세가 필요하다는 것입니다.
< 학습목표 >
- 변수의 기초 개념에 대해 설명할 수 있습니다.
- 바인딩 개념과 실효 범위를 이해함으로써, 프로그램 내에서 변수가 언제, 어떻게 사용되는지를 적용할 수 있습니다.
< 학습내용 >
- 변수 기초
- 바인딩
- 형 검사
- 변수의 실효 범위와 초기화 구문 소개
1. 변수기초
(1) 이름 (Name)
프로그램에서의 이름이란 , 프로그램 내에서 개체(Entity) 를 정의하는데 사용되는 문자들의 집합, 즉 문자열(String) 로서, 식별자(Identifier) 라고 부르기도 합니다 .
프로그래밍 언어에서 이름을 짓는 방법은 프로그래밍 언어 고유의 규칙에 따르게 됩니다. 여기서 규칙이란, 이름의 길이, 이름을 짓는데 사용되는 문자나 기호, 대소문자 사용 규칙 등을 일컫습니다. 특히 대소문자 사용 규칙은, 똑같은 문자나 기호로 이루어진 이름일지라도 대문자가 사용되었느냐, 소문자가 사용되었느냐에 따라 다른 이름으로 인식하는 것을 말하며, 이를 가리켜 ' Case Sensitive ' 하다고 합니다.
다음은 같은 문자로 이루어진 다양한 이름의 모양입니다.
- APPLE, Apple, apple
- RedApple, Red_Apple, redapple, REDAPPLE
이름을 결정할 때에는 읽기 쉽게 하는 것이 좋습니다. 여러분은 위 예의 두 번째 문장에 있는, red apple 을 표현한 변수의 이름 중에 가장 보기 좋아 보이는 것이 무엇입니까? 대부분 Red_Apple 이 가장 좋아 보인다고 하실 겁니다. 이와 같이, 보기 좋아 보이는 것이 읽기 쉽고 좋은 이름의 모양입니다
(2) 특수어 (Special Words)
특수어는 프로그램 내에서 특별한 의미를 갖고 사용되는 단어들을 말합니다. 이들은 프로그램을 보다 읽기 쉽게 해줍니다. 특수어에는 크게 키워드(Keyword) 와 예약어(Reserved Word) 의 두 가지가 있습니다.
키워드
키워드는 어떤 문맥에서만 특별한 의미를 지니고 있는 단어입니다. 키워드를 사용하는 FORTRAN 의 예를 들어 보겠습니다.
REAL APPLE
REAL = 3.4
위의 예에서 보시는 바와 같이, 'REAL' 이라는 단어 뒤에 이름이 오면, 'REAL' 은 실수형을 의미하는 키워드입니다. 그러나, 'REAL' 다음에 연산자가 오면 변수로 간주됩니다. 이 경우 특정 단어가 프로그램의 문맥에 따라 서로 다른 용도로 쓰이기 때문에 애매할 수 있고, 따라서 ' 읽기 쉬움' 에 문제가 있다고 볼 수 있습니다.
예약어
예약어는 변수의 이름으로 쓰일 수 없는 프로그래밍 언어의 특별한 단어입니다. 이 점이 키워드와 예약어의 차이입니다. 키워드와 예약어의 차이를 예와 함께 이해해 봅시다.
REAL INTEGER (FORTRAN) → ○ INTEGER APPLE (FORTRAN) → ○
int APPLE (C) → ○
float ORANGE (C) → ○
int float → Ⅹ
첫째, 둘째 문장은 실수형 INTERGER 와 정수형 APPLE 이라는 이름의 변수를 선언한 것입니다.
셋째, 넷째 문장은 각각 정수형, 실수형 변수를 선언한 것이며, 'int' 나 'float' 는 예약어로서, 변수의 이름이 될 수 없습니다.
(3) 변수 (Variables)
컴퓨터 프로그래밍 언어에서의 변수의 의미는, 컴퓨터 기억 장소를 가리키는 추상적인 표현방법입니다 . 즉 , 기억 장소의 주소를 상징화한 것 입니다. 변수에 대한 정의가 아직까지 정확하게 이해되지 않는 분들이 많으시리라 생각됩니다.
다른 예에 빗대자면 이렇습니다. ' 동경 135˚, 북위 37.5˚' 가 메모리 주소라면, ' 한국(Korea)' 은 이를 나타내는 변수( 정확히 변수의 이름) 가 되는 것입니다.
변수는 다음과 같은 속성을 가지고 있습니다.
이름 (Name)
호칭입니다.
주소 (Address)
연결되는 메모리의 위치를 말합니다. 이 때, 변수가 나타내는 메모리 위치는 항상 동일하지 않습니다. 즉, 동일한 이름을 가진 변수라도 이 변수가 각기 다른 용도로 쓰일 때에는 서로 독립적인 개체로 보고, 이들 변수가 가리키는 주소도 서로 다르게 됩니다. 변수의 주소를 가끔 'l-value' 라고도 하는데, 이는 할당문에서 변수가 좌변에 위치한다는 사실에 기인한 것입니다.
값 (Value)
값은 변수와 연결된 메모리 위치에 담겨 있는 내용을 말합니다. 'Apple' 이라는 이름을 가진 변수의 메모리 주소가 '00DE' 이고, 이 공간에 저장된 내용이 실수 '3.41' 라고 하면, 이것이 바로 변수의 값이 되는 것입니다. 변수의 값을 가리켜 'r-value' 라고도 합니다.
자료형 (Type)
자료형은 변수가 가질 수 있는 값의 범위와 적용 가능한 연산자의 집합을 결정합니다. 예를 들어, C 언어에서 'int' 자료형은 -32768~32767 까지의 범위에 해당하는 값을 가질 수 있으며, 사칙연산 및 라이브러리 함수로 제공되는 연산자를 사용할 수 있습니다.
2. 바인딩
(1) 바인딩의 개념
바인딩이란 개체 (Entity)와 속성 (Attribute) 사이 또는 연산자와 상징기호 (Symbol) 사이의 관계를 명시해 주는 것 을 말하며 , 이러한 바인딩이 일어나는 때를 바인딩 시간 (Binding Time) 이라고 합니다 .
발생하는 상황
- 언어 설계 (Language Design) 시
- 언어 구현 (Language Implementation) 시
- 컴파일 (Compile) 시
- 링크 (Link) 시
- 로드 (Load) 시
- 실행 (Runtime) 시
종류
- 변수에 대한 속성 바인딩
- 형 (Type) 바인딩
- 장소 (Storage) 바인딩
바인딩 종류에 따른 내용은 곧 자세히 다루도록 하겠습니다.
(2) 변수에 대한 속성 바인딩
프로그램 수행 시간 이전에 바인딩이 결정되어서 프로그램 수행 중에는 변하지 않는 것을 정적 바인딩(Static Binding) 이라고 하고, 프로그램이 수행되는 동안 바인딩이 일어나서 바인딩의 변화가 일어날 수 있는 것을 동적 바인딩(Dynamic Binding) 이라고 합니다.
가상적인 메모리 환경에서 변수를 기억 장소 공간에 실제 바인딩하는 작업은 복잡합니다. 왜냐하면, 기억 장소 공간이 위치하는 주소 공간의 페이지(Page) 나 세그먼트(Segment) 가 프로그램이 실행되는 동안 메모리 유효 범위를 넘나들 수 있기 때문입니다. 그러므로, 그러한 변수들은 반복적으로 바인딩하고 바인딩을 해제하는 작업이 필요합니다. 하지만 이러한 바인딩은 컴퓨터 하드웨어가 담당하기 때문에, 프로그램이나 프로그램 사용자들은 이를 전혀 고려하지 않아도 됩니다.
따라서, 앞으로는 정적 바인딩과 동적 바인딩을 구별하는데 초점을 두겠습니다.
(3) 형 바인딩 (Type Binding)
변수는 프로그램 내에서 참조되기 전에, 특정한 자료형과 바인딩 되어야 합니다. 형 바인딩에서는 자료형이 명시되는 방법과 바인딩 시간이 중요하게 고려됩니다.
변수 선언 (Variable Declarations)
명시적 선언(Explicit Declaration) 은 프로그램 내에서 변수의 이름과 그에 해당하는 특정 자료형을 명시하는 방법입니다. 이에 반해 묵시적 선언(Implicit Declaration) 은 선언문을 사용하지 않고 사전에 정한 자료형으로 변수를 연결시키는 방법입니다.
대부분의 언어에서는 명시적 선언 방법을 사용하여, 프로그램 내에서 변수에 대한 선언문을 사용하고 있습니다. 그러나 FORTRAN, BASIC 등은 묵시적인 선언 방법을 사용합니다.
예를 들어 FORTRAN에서는 I, J, K, L, M, N 으로 시작하는 변수는 기본적으로 정수형 (INTEGER)으로 , 이들 이외의 변수는 실수형 (REAL)인 것으로 간주합니다 .
두 선언 모두 자료형에 대해 정적 바인딩을 수행합니다.
동적 형 바인딩 (Dynamic Type Binding)
동적 형 바인딩은 변수의 자료형이 선언문에 의해 결정되는 것이 아니라, 할당문에서 할당되어지는 값에 의해 결정되는 것을 말합니다.
APL 과 SNOBOL4 언어는 동적 형 바인딩을 지원하는데, 같은 이름을 가진 변수라 할지라도
LIST ← 10.2 (1)
LIST ← 47 (2)
(1) 과 같이 할당된 값이 실수인 경우에는 LIST 는 실수형이 되고, (2) 와 같이 할당된 값이 정수인 경우에는 정수형이 됩니다. 이와 같이 하나의 변수에 대하여 여러 가지 형 바인딩이 가능합니다.
동적 형 바인딩을 지원하는 언어들은 정적 형 바인딩을 제공하는 언어들에 비해 융통성 있는 프로그래밍이 가능합니다. 그러나 자료형에 대한 오류 발견이 어렵고 수행시간이 오래 걸린다는 단점이 있습니다.
형 추론 (Type Inference)
형 추론은 프로그래머가 변수의 자료형을 따로 명시하지 않아도 수식(Expression) 을 통해 자료형을 추론하여 결정하는 것을 말합니다. 보통 형 추론에 의해 결정되는 자료형은, 수식에서 그 변수와 함께 쓰이는 상수의 자료형과 동일한 것으로 봅니다. 형 추론을 지원하는 언어로는 ML 이 있습니다.
다음 예를 통해 형 추론을 해 봅시다.
fun circumf(r) = 3.14159 * r * r; (1)
fun times10(x) = 10 * x; (2)
fun square(x) = x * x; (3)
위의 세 가지 예제를 보고 형 추론을 해 보셨습니까? 그럼 추론이 맞는지 확인해 봅시다. (1) 은 실수형입니다. 왜냐하면, 실수인 3.14159 를 곱했기 때문입니다. (2) 는 정수인 10 을 곱했기 때문에 정수형입니다. 그렇다면 (3) 은 무슨 형일까요? 여기서는 형 추론이 불가능합니다. 왜냐하면, (1) 과 (2) 의 경우에는 수식에 나타난 상수를 통해 형 추론을 할 수 있었지만, (3) 의 경우에는 형 추론의 실마리가 되는 상수가 전혀 나타나 있지 않기 때문입니다.
이와 같이 수식에 추론의 실마리가 되는 상수가 없을 때에는 프로그래머가 변수의 자료형을 명시해 주어야 합니다
(4) 저장 장소 바인딩 (Storage Buildings) 과 수명 (Lifetime)
저장 장소 바인딩이란 프로그램 수행 시에 변수의 값이 저장되어야 하는 공간을 지정하여 주는 것입니다.
변수에 바인딩 되는 메모리 셀(Cell) 은 가용 메모리로부터 선택되는 것인데, 이러한 과정을 메모리 할당(Allocation) 이라고 합니다. 이와 반대로, 변수에 바인딩 되어 있는 메모리 셀을 되돌려 주어 다시 가용 메모리로 만드는 과정을 메모리 반환(Deallocation) 이라고 합니다.
변수의 수명은 변수가 특정한 메모리 위치에 바인딩 되어 있는 기간을 가리키는 것으로, 변수가 메모리 할당을 받을 때부터 시작해서 다시 메모리를 반환할 때 끝납니다.
변수는 수명에 따라서 다음과 같이 네 가지로 분류됩니다.
정적 변수 (Static Variable)
스택 기반 동적 변수 (Stack-Dynamic Variable)
명시적 힙 기반 동적 변수 (Explicit Heap-Dynamic Variable)
묵시적 동적 변수 (Implicit Dynamic Variable)
이제부터 위에 열거한 네 범주에 속하는 변수들의 의미와 목적, 그리고 장단점에 대하여 알아보겠습니다.
정적 변수 (Static Variable)
정적 변수는 프로그램 수행 시작부터 끝까지 동일한 메모리 셀에 바인딩 되어 있는 변수를 말합니다.
정적 변수는 여러 가지 쓰임새로 사용되는데 그 대표적인 것이 전역 변수(Globally Accessible Variable) 입니다. 전역 변수는 프로그램 수행 도중에 저장 공간이 변하지 않고 그대로 유지되는 변수입니다.
정적 변수는 주소화 과정이 직접적으로 일어나므로 매우 효율적입니다. 또한, 프로그램 수행 시간 동안에는, 메모리 할당과 반환으로 인한 과부하(Overhead) 가 일어나지 않는다는 장점이 있습니다.
반면에 정적 변수를 사용하면 프로그램 내의 융통성이 감소되며, 오직 정적 변수만을 지원하는 프로그래밍 언어에서는 재귀 함수 (Recursion Function) 를 정의할 수 없습니다.
스택 기반 동적 변수 (Static-Dynamic Variable)
스택 기반 동적 변수는 선언문이 실행될 때 저장 장소 바인딩이 이루어지고, 그에 대한 자료형은 정적으로 바인딩 됩니다. 다시 말해서, 변수가 프로그램 시작 시에 바인딩 되는 것이 아니라, 프로그램을 한 줄 한 줄 수행하고 있는 동안, 변수를 선언하는 코드 부분이 나오면 그제서야 변수에 대한 저장 장소가 할당되고, 바인딩이 이루어지는 것입니다.
PASCAL 의 예를 들어 설명하여 보겠습니다. PASCAL 에서 함수는 선언부(Declaration Section) 와 코드부(Code Section) 로 정의되기 때문에, 함수가 호출되어 코드부가 실행되기 전에 선언부에 대한 처리가 먼저 이루어집니다. 또한 이러한 함수에서 선언되는 변수들을 지역 변수(Local Variable) 라고 하는데, 지역 변수들에 대한 기억 장소가 바로 이 때 할당되며 함수의 수행이 모두 끝나면 반환됩니다.
스택 기반 동적 변수는 위와 같은 작업을 수행하며, 부프로그램들이 자신들의 지역 변수 저장을 위해 동일한 기억 장소 공간을 공유할 수 있어 메모리 낭비를 줄일 수 있다는 장점이 있습니다.
반면에 기억 장소 할당과 반환으로 인해 과부하가 생기고, 함수가 호출, 복귀를 거듭하는 사이에 변수의 값이 소실될 수도 있다는 단점이 있습니다.
명시적 힙 기반 동적 변수 (Explicit Heap-Dynamic Variable)
명시적 힙 기반 동적 변수는 프로그래머가 직접 기억 장소를 할당함으로써 프로그램 수행 중에 기억 장소가 할당되거나 반환되는 방식의 변수입니다. 이 때 할당되는 메모리는 힙으로부터 선택되고, 포인터 변수를 통해 그 내용을 참조하게 됩니다.
포인터 변수는 저장 장소의 주소값과 그 저장 장소에 들어 있는 값을 모두 나타낼 수 있는 변수로, 자세한 내용은 4 장에서 다루도록 하겠습니다.
C++ 의 예를 들어, 명시적 힙 기반 동적 변수의 할당과 반환에 대하여 알아보겠습니다.
C++ 는 'new' 라는 할당 연산자가 있습니다. 'new' 의 피연산자는 자료형이 되는데, 이 자료형을 받아들여서 이에 맞는 명시적 힙 기반 동적 변수를 생성한 후에 이를 참조할 수 있는 포인터를 돌려줍니다. 그리고, 반환 연산자로 'delete' 가 있습니다. 명시적 힙 기반 동적 변수의 자료형은 컴파일 시에 결정되며 저장 장소는 프로그램 수행 시에 결정됩니다.
int *node; (1)
node = new int; (2)
delete node; (3)
(1) 에서 정수형 포인터 node 를 선언합니다. (2) 에서 정수형의 명시적 힙 기반 동적 변수가 'new' 연산자에 의해 생성되어, 여기서 돌려준 포인터를 node 에 할당합니다. (3) 에서 'delete' 연산자에 의해 기억 장소를 반환합니다.
명시적 힙 기반 동적 변수는 연결 리스트(Linked List) 나 트리(Tree) 처럼 수행 시간 동안 변수의 크기가 일정하지 않고 계속 변화하는 동적인 구조를 표현하는데 편리하게 사용될 수 있습니다. 그러나, 이러한 변수를 생성한 후에는 반드시 반환을 해 주어야 하는 등 세심한 배려가 필요하며, 포인터를 통해 값을 참조하는데 따르는 부담들도 단점으로 지적됩니다.
묵시적 동적 변수 (Explicit Heap-Dynamic Variable)
묵시적 동적 변수란, 변수에 값이 할당되었을 경우에만 힙 저장 장소에 바인딩 되는 변수입니다.
이것은 융통성이 매우 좋지만 프로그램 수행 시간 동안 과부하가 일어날 수 있고 컴파일시 오류 발견이 어렵다는 단점이 있습니다.
3. 형검사
자료형의 검사는, 연산자의 피연산자가 옳은 자료형인지를 확인하는 작업으로, 정적인 경우에는 컴파일 시에, 동적인 경우에는 프로그램 수행 시에 검사가 일어납니다.
예를 들어 % 연산자가 정수형 피연산자에 대해서만 연산이 가능하다고 했을 때, '%' 연산자와 실수가 함께 쓰이면 이는 오류가 됩니다.
이와 같이 어떤 연산자에 대하여 적합하지 않은 자료형의 피연산자가 사용되는 경우를 형오류(Type Error) 라고 합니다.
그런데 '%' 연산자와 실수 피연산자를 함께 사용하였는데도 불구하고 오류 없이 프로그램을 마칠 수 있는 경우도 있습니다. 이는 내부적으로 실수가 정수로 변환되어 사용되었기 때문입니다. 프로그램 컴파일 시, 실수 피연산자의 소수점 이하를 반올림 혹은 내림하여 연산자에 맞는 자료형으로 고쳐 프로그램 수행 자체에는 영향을 미치지 않는 것입니다. 이와 반대로, 정수를 실수로 변환하여 사용할 수도 있습니다.
이처럼 컴파일러에 의해 자료형이 자동 변환되는 것을 강제 변환(Coercion) 이라고 합니다.
이러한 형 검사는, 변수에 대한 자료형 바인딩이 정적으로 이루어질 경우 형 검사 역시 정적으로 행해지고 형 검사가 컴파일시 이루어지는데, 이를 정적 형 검사(Static Type Binding) 라고 합니다. 자료형 바인딩이 동적으로 이루어질 경우에는 형 검사가 동적으로 행해지며, 프로그램 수행 시 이루어지는데 이를 동적 형 검사(Dynamic Type Binding) 라고 합니다.
(1) Strong Typing
String typing 이란 컴파일 시와 프로그램 수행 시에 형 검사를 하여 모든 형오류가 검출될 수 있게 합니다. Strong typing 은 형오류 검출 능력이 뛰어나 신뢰성이 높으나, 융통성은 떨어집니다. 이를 지원하는 언어로는 ML 과 MIRANDA 가 있습니다.
(2) 형 호환성 (Type Compatibility)
형 호환성이란 말 그대로 변수의 자료형이 바뀌는 것을 의미합니다 . 형 호환성에는 이름 형 호환성 (Name Type Compatibility)과 구조체 형 호환성 (Structure Type Compatibility)의 두 가지 종류가 있습니다 .
이름 형 호환성
두 변수가 선언문에서 동일한 이름의 자료형으로 선언되었을 경우에만 자료형이 호환되는 것을 말합니다. PASCAL 의 예를 들어 이해해 봅시다.
type constant = integer; (1)
var
count_1 : integer; (2)
count_2 : constant; (3)
(1) 에서 'type' 은 사용자가 직접 특정 자료형을 정의하는 것입니다. 따라서, (1) 은 'constant' 라는 새로운 자료형을 선언해 준 것이고 constant 는 정수형이라는 것을 의미합니다. (2) 와 (3) 은 변수 선언문입니다. 여기서 'count_1' 은 정수형이고, 'count_2' 는 'constant' 형입니다. 그러나, 이 두 변수는 결국은 모두 정수형이기 때문에 형 호환이 일어나서 서로 값을 주고 받을 수가 있습니다.
그러나 다음과 같은 경우에는 같은 정수형이지만 형 호환이 되지 않습니다.
type constant = 1..100; (1)
var
count_1 : integer; (2)
count_2 : constant; (3)
위의 예제가 앞서 예제와 다른 점은, 'constant' 자료형이 일반 정수형이 아니라 정수형의 한 부분만을 값으로 취하는 집합형이라는 것입니다. 이 때에는 'count_1' 과 'count_2' 가 모두 정수형이긴 하지만 서로 다른 형으로 간주되어 형이 호환되지 않습니다.
구조체 형 호환성
두 변수의 자료형이 동일한 구조를 가지고 있는 경우에 자료형이 호환되는 것을 말합니다. 역시 PASCAL 의 예를 들어 이해해 봅시다.
type
celsius = real; (1)
fahrenheit = real; (2)
위의 예 (1), (2) 는 실수인 자료형을 새로 정의해 준 것입니다. (1) 과 (2) 모두 똑같은 실수형으로 정의되었으므로 자료형의 구조가 서로 같겠지요? 이것이 바로 구조체 형 호환성입니다.
구조체 형 호환성은 이름 형 호환성보다는 융통성이 있지만, 그것을 구현하기가 어렵다는 단점이 있습니다.
4. 변수의 실효범위와 초기화
프로그램 변수의 실효 범위란 변수의 값을 참조할 수 있는 범위, 즉 변수가 사용되는 문장의 범위를 말합니다. 변수의 범위는 변수를 전체 프로그램의 어느 부분에 선언했는가에 따라서 그 실효 범위가 달라지고, 이러한 변수의 실효 범위는 프로그램을 통해 얻고자 하는 결과값을 얻는 과정에 많은 영향을 미치기 때문에 매우 중요합니다.
변수를 실효 범위에 따라 나누면 크게 지역 변수 (Local Variable)와 비지역 변수 (Nonlocal Variable)로 나눌 수 있습니다 .
지역 변수는 변수가 선언된 프로그램 단일체나 함수 혹은 블록 안에서만 사용할 수 있는 변수이고, 비지역 변수는 전체 프로그램에 걸쳐 사용 가능한 변수를 말합니다. 이를 신용 카드에 빗대어 말하면, 국내 전용 카드는 해당 국가의 국내에서만 사용할 수 있습니다. 이것이 지역 변수의 의미입니다. 그러나 세계 어느 나라, 어느 도시의 상점에 가더라도 항상 사용 가능한 신용 카드가 있다면 그것이 바로 비지역 변수의 의미와 상통하는 것입니다.
(1) 정적 범위 (Static Scope)
변수의 정적 범위란, 변수의 실효 범위가 프로그램이 수행되기 전에 결정되는 방법입니다. 그렇기 때문에, 변수의 범위는 프로그램의 구조에 의해서 결정됩니다. 예를 통해 익혀 봅시다. 다음은 PASCAL 코드로 간략하게 표현한 것입니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/03/img/pl03_20_g01.gif" \* MERGEFORMATINET
위의 예에서, 'x' 라는 변수가 (1) 과 (2), 두 군데에서 사용되고 있습니다. 그렇다면, 이 두 'x' 는 같은 'x' 일까요? 아닙니다. 여러분이 보시는 바와 같이, 변수 'x' 의 선언이 (a) 와 (b) 에서 일어나고 있습니다. (a) 에서 선언된 'x' 는 프로시저 'big' 에서 선언된 것이고, (b) 에서 선언된 'x' 는 'big' 의 부프로그램인 프로시저 'sub1' 에서 선언된 것입니다. 따라서 (a) 의 'x' 는 'big' 프로시저 전체에서 유효한 변수이고, (b) 의 'x' 는 프로시저 'sub1' 에서만 유효한 변수입니다.
따라서 (1) 의 'x' 는 프로시저 'sub1' 내에서만 유효한 지역 변수이고, (2) 의 'x' 는 프로시저 'sub2' 에서 사용되고 있지만 결국은 프로시저 'big' 에서 선언된 'x' 로서, 비지역 변수에 해당합니다.
(2) 블록 (Blocks)
어떤 언어에서는 실행 코드 중간에서 새로운 정적 범위가 생성되는 것을 지원합니다. 이는 변수의 실효 범위가 최소화될 수 있도록 코드의 한 부분이 자신의 지역 변수를 가질 수 있도록 하는 것입니다. 이 때 변수의 저장 장소는 그 코드 영역이 시작될 때 할당되었다가 코드 영역이 끝나는 동시에 반환되는데, 이 코드 영역을 블록이라고 합니다. 예를 통해 블록의 의미를 이해해 봅시다. 다음의 두 예는 블록을 지원하는 C++ 코드를 간략하게 표현한 것입니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/03/img/pl03_21_g01.gif" \* MERGEFORMATINET
위의 두 프로그램은 모두 'temp' 라는 변수를 사용합니다. 보시는 바와 같이, 변수가 왼쪽 프로그램에서는 함수 내에 선언되어 있고, 오른쪽 프로그램에서는 'if' 블록 안에 선언되어 있습니다. 그러나 두 프로그램 모두 'temp' 변수가 'if' 블록 안에서만 사용되는 경우라면, 굳이 함수에서 선언하지 않고 'if' 블록 안에서 선언함으로써 변수의 실효 범위를 최소화할 수 있는 것입니다. 이것이 블록의 개념입니다.
(3) 동적 범위 (Dynamic Scope)
변수의 동적 범위는 부프로그램( 프로시저나 함수) 의 호출을 근거로 하여 변수의 실효 범위가 결정하는 방식입니다. 그렇기 때문에 프로그램 수행 시에 범위가 결정됩니다. 정적 범위에서 사용하였던 PASCAL 코드 예제를 이용하여 동적 범위에 대하여 이해해 봅시다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/03/img/pl03_22_g01.gif" \* MERGEFORMATINET
동적 범위는 부프로그램의 호출을 근거로 하기 때문에 호출 구조에 따라서 참조되는 변수가 다를 수 있습니다. 즉, 호출 구조에 따라 (*) 표시 되어 있는 'x' 가 가리키는 값이 전혀 다릅니다.
예를 들어봅시다.
- 'big'이 'sub1'을 호출하고 , 'sub1'이 'sub2'를 호출하는 경우에 'x'는 'sub1'에서 선언된 변수입니다 .
- 'big'이 'sub2'를 호출하는 경우에 , 'x'는 'big'에서 선언된 변수입니다
변수의 정적 범위와 동적 범위에 대한 보다 자세한 예제를 보고 싶으세요?
그러면 여기를 클릭하세요.
[ 정적 범위에 관한 예제]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/03/img/pl03_open4.gif" \* MERGEFORMATINET
point 참조 관계
1 x, y는 sub1의 것 , a, b는 example의 것
2 x는 sub3의 것 , a, b는 example의 것
3 x는 sub2의 것 , a, b는 example의 것
4 a, b는 example의 것
[ 동적 범위에 관한 예제]
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/03/img/pl03_open5.gif" \* MERGEFORMATINET
point 참조 관계
1 d는 main, c는 sub2, a와 b는 sub1의 것
2 d는 main, b와 c는 sub2의 것
3 c와 d는 main의 것
(4) 변수의 초기화 (Initialization)
초기화는 변수에 값을 바인딩하는 작업입니다. 즉, 선언한 변수에 값을 할당하여 주는 것입니다.
그러나 변수의 초기화와 상수의 선언을 구별할 필요가 있습니다. 다음 예제를 통해 두 의미를 구별하여 봅시다.
int first := 10; (1)
int first = 10; (2)
(1) 은 변수 초기화입니다. 반면에 (2) 는 상수를 선언한 것입니다. 위의 예제의 경우에는 연산자의 모양에 따라 쉽게 구별할 수 있는 경우입니다. 그러나, C/C++ 언어에서는, '=' 연산자를 이용하여 변수를 초기화 합니다. 대신에 상수 선언은 프로그램 도입부에 '#define' 이라는 형식을 사용하여 이루어집니다.
#define first 10
< 정리해봅시다 >
제 3 장 변수를 모두 배우셨습니다. 이 단원에서 배운 내용을 간단히 요약해 봅시다.
변수는 실제 자료를 가지고 결과물을 얻고자 할 때 사용하는 매개체입니다. 프로그래밍 언어에서의 변수는 고유의 형식이 있고 대입하는 자료의 모양에 따라 자료형이 달라집니다. 예를 들어, 정수를 대입할 때에는 변수를 정수형으로 선언하고, 문자를 대입할 때에는 문자형으로 선언하는 것입니다. 변수의 바인딩이나 실효 범위는 프로그램 결과물에 중요한 영향을 미치므로, 프로그램 구조를 잘 이해하여 프로그램 오류가 생기지 않도록 하여야 합니다.
선언되고 프로그램을 수행하기 위해서는 컴퓨터 메모리 내에 변수의 형과 저장 장소를 바인딩 하여야 합니다. 바인딩은 컴파일 또는 프로그램 수행 시 결정되는데, 이는 프로그램의 구조에 따라 달라집니다.
변수의 실효 범위 역시 프로그램 구조에 따라 정적 범위와 동적 범위로 나뉩니다.
바인딩이나 실효 범위는 프로그램 결과물에 중요한 영향을 미치므로, 프로그램 구조를 잘 이해하여 프로그램 오류가 생기지 않도록 하여야 합니다.
< 연습문제 >
1. 바인딩은 크게 정적 바인딩과 동적 바인딩으로 나뉩니다. 이 두 바인딩의 차이는 무엇일까요?
프로그램 수행 시간 이전에 바인딩이 결정되어서 프로그램 수행 중에는 변하지 않는 것을 정적 바인딩(Static Binding) 이라고 하고, 프로그램이 수행되는 동안 바인딩이 일어나서 바인딩의 변화가 일어날 수 있는 것을 동적 바인딩(Dynamic Binding) 이라고 합니다..
2. 다음 코드를 보고 변수의 참조 관계를 명시하세요.
void main()
{
int a, b, c;
…
}
void fun1(void)
{ int b, c, d;
…
}
void fun2(void)
{
int c, d, e;
…
}
void fun3(void)
{
int d, e, f;
…
}
a. main이 fun1을 호출 ; fun1은 fun2를 호출 ; fun2는 fun3를 호출 .
b. main이 fun3를 호출 ; fun3은 fun1을 호출 .
c. main이 fun2를 호출 ; fun2는 fun3을 호출 ; fun3은 fun1을 호출 .
a. a는 main, b는 fun1, c는 fun2, d, e, f는 fun3
b. a, b, c는 main, d는 fun1, e, f는 fun3
c. a, b는 main, c는 fun2, d는 fun1, e, f는 fun3
4 장 자료형
한 어린이가 미술시간에 그림을 그리고 있습니다. 하늘은 파란색, 산은 초록색, 그리고 단풍잎과 은행잎은 각각 빨간색과 노란색으로 칠하고 있습니다.
이처럼 그리는 대상에 따라서 표현하는 색깔이 다르듯이, 프로그램 상에서 처리해야 하는 데이터의 성격에 따라 이를 표현해 주는 자료형도 달라집니다. 예를 들어 가계부 프로그램에서 쓰이는 액수 표현은 정수형을, 학점 계산에 쓰이는 성적 표기법과 평점 표현에는 각각 문자형과 실수형을 이용하여야 할 것입니다. 이 외에도 우리가 처리해야 하는 데이터의 종류가 다양한 만큼이나 이를 표현하는 자료형도 다양합니다.
이 장에서는 프로그래밍 언어에서 제공하는 자료형에 관한 내용을 다룰 것입니다. 단순히 숫자나 문자를 나타내는 기본적인 자료형과 이를 응용하여 한 변수 안에 다양한 데이터 저장을 가능하게 하거나 프로그래머가 직접 메모리의 할당과 반환을 다룰 수 있게 하는 고급 자료형에 대하여 알아 보겠습니다.
처리해야 하는 데이터에 따라 올바른 자료형을 선택하는 일은 프로그램 평가에 영향을 미치는 중요한 작업입니다. 한번의 선택이 십년을 좌우한다는 말과 같이, 올바른 자료형의 선택이 전체적인 프로그램 코딩 작업의 효율성을 좌우하기도 합니다.
따라서 이번 장에서 배우시는 자료형의 형식과 쓰임새 등을 잘 익히시길 바라며, 지금 여러분 책상에 놓여 있는 자료들에는 어떤 자료형을 이용하는 것이 좋은지에 대해서 생각하시는 것도 좋은 복습이 되리라고 봅니다.
< 학습목표 >
- 기본 자료형에 대한 기본 개념에 대해 말할 수 있습니다.
- 기본 자료형을 기반으로 한 고난도의 고급 자료형을 익힘으로써, 고급 데이터를 표현할 수 있습니다.
- 실제 처리해야 하는 데이터에 알맞은 자료형을 선택할 수 있습니다.
< 학습내용 >
- 기본 자료형
- 문자열
- 배열형
- 레코드형
- 유니언형
- 집합형
- 포인터형
1. 기본자료형
자료형의 가장 기본이 되는 것, 즉 다른 자료형을 이용하여 정의되지 않는 자료형을 기본 자료형이라고 합니다. 기본 자료형에는 숫자형, 논리형, 그리고 문자형이 있습니다.
(1) 숫자형 (Numeric Type)
숫자형은 말 그대로 우리가 평소에 사용하고 있는 숫자를 기초로 하여 만든 자료형입니다. 숫자형은 대부분의 초기 프로그래밍 언어들이 이것만을 지원하기도 했을 만큼, 언어에서 기본적이고 중심적인 역할을 담당합니다.
숫자형은 다시 정수형과 실수형으로 나누어 집니다. 숫자형을 이렇게 다시 나누는 이유는, 정수형과 실수형이 차지하는 메모리의 양의 차이 때문입니다. 실수형이 정수형보다 많은 메모리를 차지한다는 사실은 상식적으로도 아실 수 있을 것입니다. 이와 같이 정수형과 실수형을 나눔으로써 메모리 낭비를 줄일 수 있습니다
정수형 (Integer Type)
정수형은 여러분이 학창시절 수학 시간에 배우신 정수의 의미를 그대로 갖고 있는 자료형입니다. 다만 프로그래밍 언어에서 사용하는 정수형은 그 범위가 제한되어 있습니다. 보통 정수형이라고 하면 -32768~32767 사이에 있는 값만을 취할 수 있습니다.
그러나 이렇게 범위가 제한적이면 문제 해결을 위한 프로그래밍의 융통성이 떨어질 수도 있습니다. 이런 문제를 개선하기 위하여 일부 프로그래밍 언어에서는 여러 가지 정수형을 제공합니다. C/C++ 언어에서 제공하는 여러 가지 정수형을 다음 표에 정리하였습니다. 단, 표의 'int' 는 C/C++ 언어에서 일반적인 정수형을 가리키는 키워드로, 값의 범위는 -32767~32768 입니다.
정수형 용도 값의 범위
short int 보다 작은 수 표현할 때 -32767~32768
long int 보다 큰 수 표현할 때 -2147483647~2147483648
unsigned 0 또는 양의 정수 표현할 때 0~65535
또한 위의 정수형의 조합형도 표현 가능합니다 . 이를테면 'unsigned long' 정수형은 값의 범위가 0~4294967295 인 정수를 표현할 수 있습니다 .
실수형 (Float Point Type)
실수형은 정확히 부동 소수점이라고 하며, 정수에서 표현하지 못하는 소수점 이하 자리를 갖는 숫자를 표현하는 자료형입니다. 다음 그림에서 보시는 바와 같이 실수형 형식은 기호부, 지수부, 그리고 소수부로 나뉘어 표현됩니다.
그러나 여러분이 이 같은 형식을 외우고 계실 필요는 없습니다. 자료형에서 가장 중요한 것은 처리하고자 하는 자료에 따라 올바른 자료형을 선택하는 것이니까요.
언어에 따라서 실수형을 표현하는 예약어 (혹은 키워드 )가 다르게 나타날 수 있습니다 . 예를 들어 C/C++에서는 'float' 라고 하는 반면 , PASCAL 이나 FORTRAN 에서는 'real' 이라고 합니다 .
십진수형 (Decimal Type)
십진수형은 정확히 고정 소수점이라고 하며, 소수점의 위치가 정해져 있는 십진수의 값을 표현하는데 사용됩니다. 고정 소수점형은 COBOL 과 같은 경영 자료를 처리하는데 사용되는 언어에서 기본 자료형으로 제공됩니다.
십진수형은 십진수 값을 저장할 수 있다는 장점이 있지만, 값의 범위에 제약이 있고 메모리 낭비가 생긴다는 단점도 있습니다.
(2) 논리형 (Bloolean Type)
논리형은 값의 범위가 참(True) 과 거짓(False) 의 두 가지 요소로만 이루어진 자료형입니다. 다음과 같은 PASCAL 변수 선언문과 변수 초기화를 살펴 봅시다.
var
yes, no : boolean; (1)
answer : true;
no : false; (2)
(1)은 'yes'와 'no'라는 논리형 변수 선언문입니다 . (2)는 (1)에서 선언한 변수에 대하여 각각 'true'와 'false'라는 값을 할당한 것입니다 .
C/C++ 언어에서는 따로 논리형을 지원하지 않고, 숫자형을 이용하여 참과 거짓을 나타냅니다.
즉 '0' 아닌 숫자들은 모두 참으로, '0' 은 거짓으로 간주합니다.
(3) 문자형 (CharacterType)
문자형은 앞서 배운 논리형이나 숫자형을 제외한 일반 문자나 기호 등을 나타내는 자료형입니다.
문자형은 컴퓨터에서 숫자 코딩 방식에 의해 저장되는데 , 가장 많이 사용되는 코딩 방식은 ASCII(American Standard Code for Information Interchange)로서 각각의 문자는 그에 해당하는 숫자로 변환되어 저장됩니다 . 예를 들어 문자 'a'는 65, '+'는 43입니다 .
2. 문자열
문자열은 일련의 문자들로 구성된 개체를 말합니다. 'a', 'b', 'c', 'd' 가 각각 문자라면, 'abcd' 는 문자열이 되는 것입니다. 그러나 문자열을 기본 자료형으로 제공하는 프로그래밍 언어는 많지 않아서, 보통은 문자들의 배열로써 문자열을 나타내곤 합니다.
(1) 문자열과 그 연산
프로그래밍 언어에 따라 문자열을 선언하는 방법이 다릅니다. 예제를 통해 프로그래밍 언어에서 제공하는 문자열 선언의 다양한 모습을 보도록 하겠습니다.
ADA 에서는 문자열이 문자들의 1 차원 배열로서 미리 정의되어 있습니다. 그리하여, 문자열의 부분참조, 관계 연산자, 할당 등의 적용이 가능합니다.
Name1(2:4) (1)
Name1 = Name1 & Name2; (2)
(1) 과 (2) 모두 Name1 이라는 문자열에 대하여 연산을 행해 준 것입니다. 여기서 주의하실 것은, Name1 은 문자열이 아니라는 것입니다. Name1 은 문자열을 값으로 갖고 있는 변수라는 것을 기억하시기 바랍니다.
(1)은 Name1에 저장된 문자열 중 2~4번째 문자를 취하라는 것입니다 . 즉 , Name1에 'Program'이라는 문자열이 저장되어 있다면 , (1) 연산의 결과는 'rog'인 것입니다 . (2)의 '&' 연산자는 문자열 접합 (concatenation) 연산자입니다 . 즉 , Name1이 'christ'이고 , Name2가 'mas'라면 , (2) 연산의 결과는 'christmas'인 것입니다 .
C/C++ 에서는 'char' 형(C/C++ 의 문자형을 'char' 형이라고 합니다) 의 배열을 사용합니다. 또한 표준 라이브러리를 통해 문자열을 위한 연산자를 제공합니다.
char *str = "apples"; (1)
strlen(apples); (2)
strcat(chris, mas); (3)
(1) 'apples' 라는 값을 갖는 문자열을 선언한 것입니다. 단, C/C++ 에서 이러한 문자열을 저장할 때에는 문자열 뒤에 '0' 이라는 숫자를 더하여, 'apples0' 이라고 저장합니다. 여기서 '0' 은 ' 널(Null)' 문자로, 문자열의 끝을 나타내는 역할을 합니다. 만약 어떤 문자열에 저장된 값이 '0' 이라면 이 문자열은 아무 값도 갖고 있지 않은 것입니다. 널문자는 컴파일러가 알아서 붙여주는 문자이므로 여러분이 문자열 저장을 위해서 문자열 뒤에 '0' 을 일일이 써줄 필요는 없습니다.
(2) 와 (3) 은 C/C++ 표준 라이브러리에서 제공하는 함수로서, (2) 는 문자열의 길이를 알려주는 함수이고, (3) 은 두 문자열을 접합하는 함수입니다.
(2) 문자열의 길이
문자열의 길이를 정하는 방법에는 정적(Static) 방법과 동적(Dynamic) 방법이 있습니다.
정적 방법, 즉 정적 길이 문자열(Static Length String) 이란, 문자열의 길이를 선언문에서 미리 정해 주는 것을 말합니다. 선언문에서 미리 정해준 문자열의 길이는 프로그램이 수행되는 동안에도 변하지 않고 그 길이를 그대로 유지합니다. FORTRAN, COBLE, PASCAL, ADA 등에서 이 방식을 따르고 있습니다. FORTRAN 의 예를 들어 봅시다.
character(len = 15) Name1, Name2;
위의 선언문은 길이가 15인 문자열 'Name1'과 'Name2'를 선언한 것입니다 .
동적 방법은 다시 두 가지로 나뉘는데 , 하나는 제한적 동적 길이 문자열 (Limited Dynamic Length String)이고 , 다른 하나는 동적 길이 문자열 (Dynamic Length String)입니다 .
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_10_g01.gif" \* MERGEFORMATINET
제한적 동적 길이 문자열이란, 문자열 길이의 최대값을 주고 이 범위 내에서는 길이를 자유롭게 지정할 수 있는 것을 말합니다. C/C++ 에서 이러한 방법을 제공하는데, 예를 들어, 문자열 변수를 정의할 때 길이를 15 로 선언해 주면, 문자열의 길이가 0~15 인 문자열을 값으로 가질 수 있습니다.
동적 문자열 길이란, 문자열의 길이 제한이 전혀 없는 것을 말합니다. 그러나 이 방법은 문자열 저장 장소의 할당과 반환에서 비롯되는 과부하가 생기는 단점이 있습니다.
3. 배열형
배열형은 같은 형의 자료들이 모여서 이루어진 자료형입니다. 쉽게 고등학교 수학 교과 과정에 포함되어 있는 행렬을 생각하시면 됩니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_11_g01.gif" \* MERGEFORMATINET
위 배열은 3Ⅹ3(3 행 3 열) 배열로서, 배열을 이루는 각각의 원소들은 자신의 위치를 행과 열로써 나타내고 있습니다.
프로그래밍 자료형으로 쓰이는 배열도 배열 자체의 이름과 그 배열의 원소의 위치를 나타내는 첨자(Index) 라는 것이 있어서 위와 같은 배열의 형태를 얼마든지 나타낼 수 있습니다. 이에 관해서는 다음 절에서 배우기로 하겠습니다. 다만, 배열형에 관한 본격적인 내용에 들어가기 전에 여러분이 기억하셔야 할 것은, 배열형은 그 배열을 이루는 자료형이 모두 같아야 한다는 것입니다.
(1) 배열형과 그 연산
배열의 의미는 같아도 프로그래밍 언어에 따라서 배열형을 표현하는 방법이 다릅니다. 따라서 이번 절에서는 배열형의 선언과 그 연산에 대하여 살펴보도록 하겠습니다.
int one_dimension[5]; (1)
char two_dimension[10][10]; (2)
one_dimension[3]=1024; (3)
one_demension[0] = one_dimension[1] + one_dimension[2]; (4)
two_dimension[4][5]='k'; (5)
위에 보이는 배열 선언은 C/C++ 코드 예제로, (1) 은 5 개의 정수형 원소를 갖는 1 차원 배열을 선언한 것이고, (2) 는 100 개의 문자형 원소를 갖는 2 차원 배열을 선언한 것입니다. 단, 배열의 첨자는 '0' 부터 시작합니다. 따라서 (1) 의 경우 배열의 첫번째 원소의 첨자는 '0' 이고 마지막 원소의 첨자는 '4' 가 되어 모두 5 개의 원소가 되는 것입니다. 2 차원 배열도 마찬가지 입니다. 2 차원 배열의 첫번째 원소와 마지막 원소의 첨자가 어떻게 되는지 여러분이 직접 생각해 보십시오.
해설은 여기에 있습니다.
(3), (4), (5) 는 배열 원소의 연산을 나타낸 것인데, 배열 원소에 대한 연산은 그 배열을 이루고 있는 기본 자료형에 따라 달라집니다. 배열을 이루고 있는 기본 자료형이 정수형이나 실수형이면, 이들 자료형이 제공하는 연산들을 사용할 수 있고, 문자형이면 문자형에 제공되는 연산들을 사용할 수 있는 것입니다. (3) 은 배열의 네 번째 원소에 값을 할당한 것이고, (4) 는 배열의 원소를 가지고 덧셈 연산을 한 것입니다. (5) 는 다섯번째 행 여섯번째 열 위치에 있는 원소에 문자 'k' 를 할당한 것입니다. 그림으로 표현하면 다음과 같습니다.
다음 예제는 PASCAL의 예입니다 .
type
RealArray = array [1..8] of Real; (6)
var
X : RealArray; (7)
(6) 은 8 개의 원소를 가진 실수형 1 차원 배열을 정의해 준 것이고, (7) 은 (6) 과 같은 배열 구조를 갖는 변수를 선언한 것입니다. 따라서 이 배열을 가지고 실제 연산을 할 때에는 X[3] 과 같이 변수와 그에 해당하는 첨자를 사용하여 수식을 표현합니다. 단, PASCAL 에서 첨자의 시작은 '1' 입니다.
(2) 배열의 초기화
배열을 초기화 할 때에는 배열의 원소마다 일일이 값을 할당하여 주면 되지만, 일부 프로그래밍 언어에서는 배열형만의 특별한 초기화 방법을 제공하고 있습니다.
int list[ ] = {0, 5, 5}; (1)
char names[ ] = {"Joe", "Bob", "Jane"}; (2)
위의 예제는 C/C++ 에서의 배열 초기화를 나타낸 것입니다. C/C++ 에서는 보시는 바와 같이 배열 선언과 동시에 배열을 초기화 하는 것이 가능합니다. (1) 은 0, 5, 5 라는 세 개의 정수 원소를 갖는 배열 'list' 를 선언한 것입니다. 보통 배열을 선언할 때 '[]' 안에 배열 원소의 개수를 지정해 주어야 하지만, (1) 과 같이 배열을 선언해 줄 경우에는, 컴파일러가 알아서 '{}' 안의 원소의 개수를 세어서 배열의 첨자를 3 으로 지정해 줍니다. (1) 을 같은 의미의 다른 명령으로 다시 표현하면 다음과 같습니다.
int list[3];
list[0] = 0; list[1] = 5; list[3] = 5;
그러니 (1) 과 같은 표현이 프로그래머 입장에서 봤을 때 얼마나 편리함을 제공하는 것인지 짐작이 가시지요?
(2) 는 문자열을 원소로 갖는 문자열 배열이며, 역시 의미는 (1) 과 같습니다.
그러나 PASCAL 은 위와 같은 배열 초기화 방법을 제공하지 않습니다. 따라서 배열 선언과 배열 원소의 값 할당을 차례로 표현해 주어야 합니다.
(3) 배열의 연산자
앞에서 배운 연산자가 배열을 이루고 있는 원소에 대한 연산이었다면, 이번 절에서 언급되는 배열 연산자는 배열 자체의 연산자입니다. 다시 말해서 배열을 하나의 단위로 취급하여 배열과 배열끼리의 연산을 행하는 것입니다.
ADA 에서 '&' 연산자는 배열 접합 연산자이며, FORTRAN90 에서 '+' 연산자는 두 배열에서 같은 위치에 있는 각 원소들 쌍에 대한 합을 구하는 연산자입니다.
4. 레코드형
레코드형은 서로 다른 형의 원소들이 하나의 집합으로 표현된 것을 말합니다. 예를 들어, 고객 관리 프로그램을 만들고 싶어하는 판매 회사가 있다고 해 봅시다. 고객 관리 프로그램을 유지하기 위해 필요한 고객 정보에는 아이디(ID), 이름, 나이, 전화번호가 있다고 했을 때, 이 정보는 각각 다른 자료형으로 표현되기 때문에 이것을 자료형에 따라 따로 저장하면 무척 불편할 것입니다. 이처럼 각기 다른 자료형을 한데 묶어 하나의 자료형으로 표현할 수 있는 것이 레코드형입니다.
PASCAL 의 예를 들어 직접 프로그래밍 언어로 표현해 봅시다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_15_g01.gif" \* MERGEFORMATINET
위와 같이 정의된 레코드형을 가지고 직접 고객 정보를 입력하면 다음과 같이 저장됩니다.
Customer1.ID 0001
Customer1.Name Mary Jones
Customer1.Age 25
Customer1.Phone 515-658-9711
(1) 레코드 필드 (Field) 의 참조
앞 절에서 고객 정보 레코드형을 정의하고, 그 정보를 저장하였습니다. 그런데, 어떤 고객의 전화번호가 바뀌었습니다. 이처럼 레코드의 필드를 수정할 필요가 생겼을 때, 그 필드만을 참조해야 하는 상황이 발생합니다.
레코드의 필드를 참조하는 방법은 두 가지가 있습니다. 이 방법들을 특별히 지칭하는 용어는 없습니다. 따라서 참조 형태를 비교해 보시고 이해하시기 바랍니다.
PHONE OF CUSTOMER1 (COBOL)
Customer1.Phone (PASCAL 외 대다수 언어 )
위에서 보시는 바와 같이 COBOL 에서는 하위 그룹부터 참조하지만, PASCAL 과 대부분의 언어에서는 상위 그룹부터 참조합니다.
자, 이제 전화번호 필드를 바꿔 볼까요?
Customer1.Phone := 212-643-5895;
(2) with 문 (with Statement)
with 문은 PASCAL 에서 제공하는 것으로, 레코드의 필드를 모두 채울 때 사용하는 문입니다. with 문을 이용하여 고객 정보를 채워 보겠습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_17_g01.gif" \* MERGEFORMATINET
위의 with 문은 다음 할당문과 같은 의미를 갖습니다.
Customer1.ID := 0045;
Customer1.Name := 'Bob Kane'; Customer1.Age := 42; Customer1.Phone := '955-879-2580';
레코드 필드에 값을 할당할 때에는 일반적인 할당문이나 with 문 모두 사용이 가능하기 때문에 여러분이 사용하기 편한 것을 골라 쓰시면 됩니다.
5. 유니언형
유니언형은 프로그램이 수행되는 동안 저장되는 자료형이 바뀔 수 있는 자료형을 일컫는 것으로, FORTRAN, PASCAL, ADA, C/C++ 등에서 유니언형을 지원하고 있습니다.
PASCAL 예제를 통하여 유니언형의 이해를 돕도록 하겠습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_18_g01.gif" \* MERGEFORMATINET
위의 예제를 보시고 직접 설명하실 수 있겠습니까? 아마 충분히 하실 수 있으실 거라 믿습니다. 그럼 여러분의 생각과 답이 맞는지 하나씩 살펴 보겠습니다.
예제 코드를 살펴 보시면 , '아마 넓이를 구하기 위한 코드일 것 '이라는 상상을 하셨을 것입니다 . 첫째 줄에 있는 'shape'은 'circle', 'triangle', 'rectangle'이라고 정의되어 있습니다 . 둘째 줄의 'object'는 레코드로서 , 'shape'에 따라 서로 다른 필드들을 갖게 되는데 , 'circle'의 경우 지름을 뜻하는 'diameter'라는 필드를 갖게 되고 , 'triangle'의 경우 두 변과 그 사이에 끼인 각을 뜻하는 'leftside', 'rightside', 'angle' 이라는 필드를 갖습니다 . 위의 with 문은 다음 할당문과 같은 의미를 갖습니다 .
Figure.diameter := 9.45; {'shape'이 'circle'일 경우의 레코드 필드 할당 }
Figure.side1 := 10; {'shape'이 'rectangle'일 경우의 레코드 필드 할당 } Figure.side2 := 20;
6. 집합형
대개의 자료형이 그렇듯이, 집합형도 수학 교과과정에서 배우신 집합을 연상하시면 이해하기 쉽습니다. 집합형이란 변수들이 기본 자료형이라고 하는 몇몇 자료형으로부터 서로 다른 값들을 순서 없이 저장할 수 있는 자료형을 말합니다. 집합형은 PASCAL 과 MODULA-2 에서 제공됩니다.
여기서는 친숙한 PASCAL 의 예를 들어 설명하겠습니다.
type colors = (red, blue, green, yellow, white);
colorset = set of colors;
var set1, set2 : colorset;
첫째 줄의 'colors'는 전체집합에 해당합니다 . 'colorset'은 'colors'를 전제집합으로 하는 집합형입니다 . 따라서 'colorset'으로 선언된 변수 'set1'과 'set2'는 'colors'에 있는 원소들을 바탕으로 집합을 이룰 수 있습니다 .
집합에 대한 할당은 다음과 같습니다.
set1 := [red, blue, yellow];
set2 := [red, white, green];
집합 연산자
집합 연산자 역시 수학 교과 과정에서 배운 집합 연산자의 의미를 그대로 살린 것들입니다. 아래 표에 주요 집합 연산자를 정리하였습니다.
연산자 의미
+ 합집합
* 교집합
- 차집합
<= 부분집합
이 외에 멤버쉽(Membership) 연산자 'in' 이라는 것이 있습니다. 이 연산자는 원소가 집합에 속한다라는 것을 나타낼 때 사용하는 연산자입니다.
green in set2;
위의 예제는 'green'이 set2에 속한다라는 의미입니다 .
7. 포인터형
포인터형이란 메모리 주소와 특별한 의미를 갖고 있는 'nil' 로 구성된 변수입니다. 여기서 'nil' 은 현재 포인터가 어떤 객체도 참조하고 있지 않다는 것을 의미합니다.
포인터는 간접 주소 방식의 장점을 제공하고, 동적 저장 장소 관리를 위해 설계되었습니다. 3 장 변수에서 배우신 힙 기반 동적 변수를 선언할 때, 바로 이 포인터형을 사용합니다.
포인터는 프로그래머가 직접 저장 장소를 할당, 반환해 주어야 하므로 꼼꼼한 프로그램 작성 능력을 필요로 합니다. 또한 배워야 할 내용이 많고 조금 어렵다는 것을 미리 숙지하시고, 내용 이해에 좀 더 많은 노력과 시간을 투자하시기 바랍니다.
(1) 포인터 유형과 연산
프로그래밍 언어마다 제공하는 포인터의 유형과 연산이 다릅니다. 이 절에서는 PASCAL 과 C/C++ 를 비교하여 설명하겠습니다.
포인터형의 선언
포인터형의 변수를 선언하는 방법은 다음과 같습니다.
char *p; (C/C++)
var P : ^Real (PASCAL)
위에서 보시는 바와 같이, C/C++ 에서는 '*' 연산자를 사용하여 포인터형을 선언하고, PASCAL 에서는 '^' 연산자를 사용하여 선언합니다.
포인터형의 할당과 반환
포인터형 변수를 선언했다고 해서 포인터를 사용할 준비가 완전히 다 끝난 것은 아닙니다. 포인터를 선언하고 나서는 포인터에 가용 메모리를 할당해 주어야 합니다.
C/C++, PASCAL 모두 메모리를 할당하는 함수들을 갖고 있습니다. 앞 절에서 선언한 변수들을 가지고 메모리를 할당하는 작업은 다음과 같습니다.
p = malloc(char); (C/C++)
New(P); (PASCAL)
변수들을 모두 사용하고 나면 메모리를 다시 반환하여야 하는데, 이 때에도 미리 정의된 함수를 사용합니다. 프로그래밍 언어에 따른 반환 함수는 다음과 같습니다.
free(p); (C/C++)
dispose(P); (PASCAL)
포인터 변수에 의한 참조
포인터 변수는 할당(Assignment) 과 역참조(Dereferencing) 라는 두 가지의 기본적인 연산을 제공합니다. 할당은 포인터 변수가 저장되어 있는 메모리 주소를 가리키는 것이고, 역참조는 변수가 바운드된 메모리 주소에 담긴 값( 혹은 객체) 을 가리키는 것입니다. 다시 말하면, 포인터가 가리키고 있는 것은 메모리 주소이고, 이 메모리 주소에 포인터 변수의 실제 값이 들어 있는 것입니다. 이를 그림으로 표현해 보겠습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/04/img/pl04_25_g01.gif" \* MERGEFORMATINET
여러분이 프로그램을 수행할 때에 원하는 결과물을 얻기 위해서는 변수가 저장된 주소가 필요한 것이 아니라 메모리에 저장된 값이 필요합니다. 그렇다면, 이 값은 어떻게 참조할 수 있는 것인지 알아 보겠습니다.
*p = 'A' (C/C++)
p^ := 15.0; (PASCAL)
C/C++ 에서는 '*' 기호를 변수 앞에 붙여주면, p 가 가리키고 있는 주소를 가진 저장 장소에 'A' 라는 문자를 저장하라는 것입니다. PASCAL 에서는 '^' 기호를 붙이면 됩니다. 이는 저장되어 있는 값을 가져올 때에도 마찬가지 입니다.
그러나 변수에 어떠한 기호도 붙이지 않고 변수 이름 자체만을 사용하게 되면, 그것은 포인터 변수가 가리키는 주소값을 의미합니다. 예를 들어
value := P; (PASCAL)
과 같은 문장의 의미는, 'value' 에 P 가 가리키고 있는 주소값을 할당하라는 것입니다. 만약 위의 그림과 같이 P 가 가리키고 있는 주소값이 1000 번지라면, 'value' 에 저장되는 값은 1000 이 되는 것입니다. C/C++ 에서는 변수의 이름 앞에 '&' 연산자를 사용하여 변수의 주소값을 돌려주게 됩니다.
(2) 포인터의 문제점
포인터를 사용하다 보면 몇 가지 문제가 발생하게 됩니다.
다음을 클릭해보세요.
형검사 (Type Checking)
포인터가 가리킬 수 있는 객체의 자료형을 포인터의 도메인 형(Domain Type) 이라고 합니다. 예를 들어 정수형 포인터는 정수형 객체만을 가리킬 수 있습니다. PL/I 라는 프로그래밍 언어는 포인터가 하나 이상의 도메인 형을 가질 수 있도록 하는데, 이처럼 도메인 형이 하나로 정해지지 않을 경우에는 정적인 자료형 검사가 불가능하여 프로그램 상에 오류가 생길 위험이 많습니다.
허상 포인터 (Dangling Pointer)
허상 포인터는 포인터가 이미 반환된 동적 변수의 주소를 갖고 있는 것을 말합니다. 이미 반환된 기억 장소에는 유효하지 않은 데이터가 들어 있거나, 이미 다른 동적 변수의 데이터가 들어 있을 수도 있기 때문에 허상 포인터의 참조는 프로그램 오류를 유발시킬 수 있습니다.
객체소실 (Lost Object)
객체 소실이란 포인터가 가리키는 객체가 유효한 데이터를 갖고 있지도 않고, 유효한 데이터를 갖고 있더라도 이에 접근할 수 없는 경우를 말합니다. 이러한 변수를 가비지(Garbage) 라고 합니다.
< >
제 4 장 자료형를 모두 배우셨습니다. 이 단원에서 배운 내용을 간단히 요약해 봅시다.
자료형은 크게 기본 자료형과 이를 구조화한 고급 자료형이 있습니다.
기본 자료형은 숫자형, 논리형, 문자형이 있으며, 이를 구조화한 고급 자료형에는 배열형, 유니언형, 레코드형, 집합형, 포인터형 등이 있습니다.
자료형은 프로그래머가 처리하고자 하는 자료의 성격에 따라 그 선택 기준이 달라집니다.
- 나이, 소수점이 없는 숫자들의 단순 덧셈, 뺄셈, 곱셈을 처리할 때에는 ☞정수형
- 소수점이 포함된 수식 계산을 할 때에는 ☞ 실수형
- 이름, 제목 같은 문자나 문자열을 처리해야 할 때에는 ☞ 문자형이나 문자열형을 선택할 수 있습니다.
하는 자료가 많아지고 복잡해짐에 따라 이를 잘 표현할 수 있는 자료형도 등장하였는데, 이를 사용할 때에는 그 자료형의 형태와 성질 등을 잘 파악해야 합니다.
예를 들어 레코드형과 유니언형 중 하나를 골라서 선택해야 하는 상황이 발생했을 때에
- 프로그램을 수행할 때마다 자료형의 구조가 달라져야 하는 경우 ☞ 유니언형
- 프로그램의 시작부터 끝까지 자료형의 구조가 동일한 경우 ☞ 레코드형
을 선택하는 것이 좋습니다.
변수가 저장되는 메모리 주소와 그 값을 표현하는 자료형으로서, 포인터 변수를 사용할 때에는 반드시 사용자가 가용 메모리를 할당, 반환해 주어야 합니다. 그리고, 변수의 표현법에 따라 주소값을 할당할 수도, 주소에 들어 있는 객체의 값을 할당할 수도 있으므로 원하는 값에 따라 정확하게 표기하여야 프로그램 결과에 오류가 없습니다.
< 연습문제 >
1. 다음 중 기본 자료형에 속하지 않는 것은 무엇일까요?
① 숫자형 ② 문자형 ③ 십진수형 ④ 집합형
답은 ④번입니다.
2. 다음 데이터는 학생 정보 데이터입니다. PASCAL 코드를 이용하여 알맞은 자료형으로 표현해 보세요.
학번 0012345
이름 Bill Edward
학과 CSE
나이 21
평점 3.3
type
IDRange = 00000001..9999999;
StringType = packed array [1..13] of Char;
Student = record
end;
ID : IDRange;
Name : StringType;
Dept : StringType;
Age : Integer;
Grade : Real
3. 포인터형이 기존 자료형과 다른 점은 무엇일까요?
포인터 형은 프로그래머가 직접 메모리에 접근하여 메모리 할당, 반환을 할 수 있습니다.
4. 포인터형은 포인터가 가리키고 있는 메모리 주소값과 메모리에 저장된 객체를 참조할 수 있습니다. C 코드에서, 변수 ptr 로 메모리 주소값을 참조하는 방법과 메모리에 저장된 객체를 참조하는 방법을 기술해보세요.
주소값 참조 : &ptr, 객체 참조 : *ptr.
제5 장 수식과 할당문
요리책을 보면, 요리 재료, 조리법, 그리고 그에 의해서 만들어진 음식 사진이 있습니다. 여러분이 4 장에서 배운 변수가 요리 재료라면, 5 장과 6 장에서 배우실 내용은 바로 조리법입니다. 좋은 음식을 만들려면 좋은 재료를 선택하는 것도 중요하지만 그 재료를 가지고 알맞은 조리법으로 요리를 만드는 것도 중요하겠지요.
이번 장에서 배우실 조리법은 수식과 할당문입니다.
수식은 프로그래밍 언어로 계산(Computation) 을 명시하는 기초적인 수단입니다. 따라서 프로그래머에게 있어서 수식의 문법과 의미를 둘 다 이해하는 것은 매우 중요합니다. 수식을 잘 이해하려면 무엇보다 연산자와 피연산자의 관계와 계산 순서에 역점을 두고 학습하시는 것이 좋습니다.
할당문은 어떤 메모리 셀로부터 가져온 값을 다른 메모리 셀에 저장하는 방법입니다. 다른 표현으로는 값을 변수에 바인딩한다고도 합니다. 이러한 할당문은 대개 연산자가 있는 수식을 포함하고 있으며, 수식의 결과값이 메모리에 저장됩니다.
< 학습목표 >
- 수식의 형태와 의미에 대해 설명할 수 있습니다.
- 할당문의 형태와 의미에 대해 설명할 수 있습니다.
< 학습내용 >
- 수식
- 할당문
1. 수식
수식은 크게 산술식, 관계식, 논리식이 있습니다. 이들 각각에 대한 설명과 함께 여기에 사용되는 연산자와 피연산자, 그리고 이들의 표현법과 의미에 대해서 알아보겠습니다.
(1) 산술식 (Arithmetic Expressions)
산술식은 우리가 접하는 사칙 연산 및 기타 수학적 계산을 수행하기 위한 것으로서, 연산자, 피연산자, 괄호, 그리고 함수 호출로 이루어진 구조체입니다.
연산자 (Operator)
연산자는 피연산자의 개수에 따라 세 가지로 나뉩니다.
다음을 클릭해보세요.
단항연산자 :
피연산자가 하나인 연산자입니다. 대개 변수의 부호를 나타낼 때 사용합니다.
예 ) -A, +B
이항연산자 :
피연산자가 두 개인 연산자로 가장 흔히 볼 수 있는 수식의 형태입니다.
예 ) A + B, A * B + C
삼항연산자 :
피연산자가 세 개인 연산자입니다. 삼항 연산자는 C/C++ 에서 지원하며, if-then-else 구문을 대신해서 사용됩니다.
예 ) expr1 ? expr2 : expr3 a expr1이 참이면 , expr2를 수행하고 그렇지 않으면 expr3를 수행합니다 .
우선순위 (Precenence)
연산자에 따라 계산 우선순위가 있습니다. 흔히 수학적 계산식에서 쓰이는 연산자 우선순위가 비슷한 순서를 가지며 우선순위는 다음과 같습니다.
FORTRAN
PASCAL
C/C++
ADA
Highest
Lowest
**
*, /, div, mod
postfix ++, --
**, abs
*, /
all +, -
prefix ++, --
*, /, mod
all +, -
unary +, -
unary +, -
*, / ,%
binary +, -
binary +, -
위의 표에서 생소하게 보이는 연산자들이 있을 것으로 생각됩니다. 이러한 연산자들은 부분적으로 이 단원 전체에 걸쳐서 나오는 예제를 통해 익히실 수 있으므로, 여기에서는 더 깊이 들어가지 않겠습니다.
결합도 (Associativity)
수식에 두 개 이상의 연산자가 존재하고 그것이 같은 연산자 우선순위를 가질 때, 어느 연산자를 먼저 계산하는가 하는 규칙을 결합도라고 합니다.
대부분의 언어에서의 결합도는 좌결합입니다. 즉, 수식의 왼쪽부터 연산을 하는 것입니다. 그러나, 다음과 같은 거듭제곱의 꼴에서는 우결합입니다.
A ** B ** C;
위의 식은 B 의 C 제곱을 먼저 계산한 후에 이 값만큼 A 의 거듭제곱을 합니다. 만약 이러한 결합도를 지원하지 않는 언어이거나, 프로그래머가 직접 연산자 우선순위를 지정해 주고 싶을 때에는 괄호를 이용합니다.
함수의 부가적 작용 (Functional Side Effect)
부가적 작용이란, 함수가 자신의 매개변수(Parameter) 를 바꾸거나 전역 변수를 바꿀 때 일어나는 현상을 말합니다. 다음과 같은 예를 통해 부가적 작용에 대해 이해해 봅시다.
A : 10;
New := A + Fun(A); (1) (2)
만약 'Fun' 함수가 함수 수행 후에도 매개변수로 사용한 'A' 의 값을 변화시키지 않는다고 하면 위의 코드는 문제가 되지 않습니다. 그러나 이 함수가 매개변수를 20 으로 바꾸는 함수라고 가정하면, 'New' 의 값은 피연산자의 우선순위에 따라 달라집니다.
위의 코드가 좌결합일 때에는 (2) 의 식의 값은 '10 + Fun(10)' 이 됩니다. 그러나 우결합일 때에는 'Fun' 함수부터 수행하게 되므로 이 함수의 수행이 끝난 후 'A' 의 값이 20 으로 바뀌어, 결과적으로 '20 + Fun(10)' 이 됩니다. 더 자세한 설명이 필요하신 분은 여기를 보세요.
부가적 작용을 해결하는 가장 좋은 방법은 프로그래밍 언어 설계자가 이러한 부가적 작용이 일어나지 못하도록 하는 언어를 개발하는 것이지만, 그렇지 못할 때에는 수식에 사용된 피연산자가 특별한 순서에 의해서 계산됨을 명시하고 프로그래머가 그 순서를 지켜줄 것을 요구하는 내용을 명시합니다.
(2) 관계식 (Relational Expression)
관계식은 관계 연산자를 가지고 두 피연산자의 값을 비교하는 식을 말합니다. 관계식은 값을 비교하기 때문에 하나의 관계 연산자와 두 개의 피연산자로 표현됩니다. 그리고 관계식의 결과값은 참, 거짓의 값을 갖는 논리값이 됩니다.
다음은 관계 연산자의 형태와 의미를 정리해 놓은 표입니다. 몇 개의 관계 연산자를 제외하고는 대부분의 언어가 같은 형태의 연산자를 갖습니다.
관계 연산자의 의미
PASCAL
C/C++
ADA
FORTRAN
같음 (Equal)
=
==
=
.EQ.
같지 않음 (Not Equal)
<>
!=
/=
.NE.
큼 (Greater than)
>
>
>
.GT.
작음 (Less than)
<
<
<
.LT.
크거나 같음
>=
>=
>=
.GE.
작거나 같음
<=
<=
<=
.LE.
관계 연산자는 수식 연산자에 비해 낮은 우선순위를 갖습니다
(3) 논리식 (Boolean Expression)
논리식은 논리형 변수, 논리형 상수, 관계식 그리고 논리 연산자로 이루어진 식을 말합니다. 수학시간에 배운 ' 명제와 식' 에서 배우셨던 논리식을 프로그래밍 언어에 맞게 표현한 것으로 생각하시면 이해하기 쉽습니다. PASCAL 에서의 논리식을 표현하여 보면 다음과 같습니다.
(A > B) and (not C) or (D<>A);
다음은 논리 연산자의 형태와 의미를 정리해 놓은 표입니다.
논리 연산자의 의미
PASCAL
C/C++
부정
not
!
논리곱
and
&&
논리합
or
||
보통 논리 연산자는 관계 연산자보다 우선순위가 낮지만, PASCAL 에서는 더 높은 우선순위를 갖고 있기 때문에, 이 때에는 괄호를 이용해야 합니다.
2. 할당문
할당문은 프로그램에서 변수에 값을 동적으로 바인딩시킬 수 있도록 해주는 문으로서, 할당문의 일반적인 구조는 다음과 같습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/05/img/pl05_10_g01.gif" \* MERGEFORMATINET
C/C++, FORTRAN 등 대부분의 프로그래밍 언어에서는 할당 연산자로 등호 (=)를 사용하지만 , PASCAL에서는 ':='를 사용합니다 .
할당문은 값이 할당되는 변수의 개수와 부가적인 역할에 따라 몇 가지로 구분될 수 있습니다.
(1) 복수 할당문 (Multiple Target)
복수 할당문이란 값이 할당되는 변수의 개수가 둘 이상인 할당문을 말합니다.
다음 예에서 보시는 바와 같이
A, B = 0; (C/C++)
이라고 쓰인 코드는, 변수 A 와 B 에 모두 '0' 을 할당하라는 의미를 가지며
이는 다음 코드와 같은 의미를 갖습니다.
A = 0;
B = 0;
(2) 조건 할당문 (Conditional Target)
조건 할당문이란 4 페이지에서 보신 삼항 연산자를 이용해 할당문에 조건을 부여할 수 있도록 하는 것을 말하는 것으로 C/C++ 에서 지원됩니다.
Flag ? Count1 : Count2 = 0
두 번째 보는 예제라 익숙하시죠? 여러분께서 직접 위 할당문을 해석해 보시기 바랍니다.
해설을 보시려면 여기를 클릭하세요.
할당문 해석 : Flag가 참이면 Count1에 '0'을 할당하고 , 거짓이면 Count2에 '0'을 할당합니다 .
(3) 복합 할당 연산자 (Compound Assignment Operator)
복합 할당 연산자는 할당 연산자와 함께 자주 사용되는 연산자를 함축적으로 표현한 연산자입니다. C 코드의 예를 들면,
Sum += Value;
는 다음과 같은 의미를 갖는 코드입니다.
Sum = Sum + Value;
즉 'Sum'에 'Sum'과 'Value'를 더한 값을 할당하라는 의미입니다 .
(4) 단일 할당 연산자 (Unary Assignment Operator)
단일 할당 연산자는 단일 할당 연산자는 단순한 정수의 증가와 감소를 함축적으로 표현한 연산자입니다. 역시 C 코드의 예를 들어 보겠습니다.
Value_1 = ++Increase; (1)
Value_2 = Reduce--; (2)
(1)의 '++'은 변수의 앞에 붙어 있기 때문에 접두 (Prefix) 연산자라고도 하며 , (2)의 '--'은 변수의 뒤에 붙어 있기 때문에 접미 (Postfix) 연산자라고 합니다 .
(1)은 'Increase'의 값을 '1'만큼 증가시킨 뒤 , 이 값을 'Value_1'에 할당하라는 의미를 지닌 것으로 다음 코드와 의미가 같습니다 .
Increase = Increase + 1;
Value_1 = Increase;
(2)는 'Reduce'의 값을 'Value_2'에 할당한 후 , 'Reduce'를 '1'만큼 감소시키라는 의미를 지닌 것으로 다음 코드와 의미가 같습니다 .
Value_2 = Reduce;
Reduce = Reduce - 1;
(1) 과 (2) 의 예제를 통해 접두 연산자와 접미 연산자의 차이도 함께 이해하셨으리라 생각합니다.
< 정리해봅시다 >
제 5 장 수식과 할당문을 모두 배우셨습니다. 3 장과 4 장은 배워야 할 내용이 너무 많아 힘들었을텐데, 이번 장은 좀 쉬웠나요? 그럼 이 단원에서 배운 내용을 요약해 봅시다.
상수, 변수, 괄호, 함수 호출, 그리고 연산자로 이루어져 있고, 할당문은 목적 변수, 할당 연산자, 그리고 수식으로 이루어져 있습니다.
언어에서 제공하는 여러 가지의 수식을 통해 여러분이 평소 수학적 계산에서 볼 수 있었던 산술식, 논리식, 관계식을 표현할 수 있습니다.
여러 가지 형태로 나타낼 수 있는데, 단순한 할당문 외에도 프로그램을 간편하게 짤 수 있게 그 의미를 함축한 할당 연산자를 이용하면 반복되는 할당문의 개수를 줄일 수 있습니다. 프로그래밍 언어를 선택할 때에는, 각 프로그래밍 언어가 갖고 있는 고유의 특성과 프로그래밍 언어의 평가 기준을 고려해야 합니다.
< 연습문제 >
1. 다음과 같이 정의된 함수를 봅시다.
function FUN (var K : integer) : integer; begin
K := K + 4;
FUN := 3 * K - 1
end;
2. 다음 프로그램 코드를 보고 물음에 답하세요.
I := 10;
SUM := (I / 2) + FUN(I);
a. 위의 수식의 결합도가 좌결합일 때, SUM 의 값을 구하세요
b. 위의 수식의 결합도가 우결합일 때, SUM 의 값을 구하세오.
a. 46
FUN (I) → FUN (10) →
begin I = 10 + 4; →
I = 14 (1)
FUN = 3 * 14 - 1; → FUN = 41
end;
좌결합일 때에는 I/2부터 계산하므로 , 이 때 대입되는 I는 10입니다 . 따라서 , 5 + 41 = 46.
b. 48 함수값은 a와 같습니다 . 그러나 , 우결합일 때에는 함수부터 계산되므로 I/2에 대입되는 I는 (1)에 의해 바뀐 14입니다 . 따라서 , 7 + 41 = 48.
3. 다음 C 코드로 된 할당문 중 그 표기법이 틀린 것을 고르세요.
① int x, y := 0;
② condition ? expr1 : expr2 = 7;
③ sum = sum + 2;
④ value -= count;
정답은 ①번 입니다.
C 코드에서는 ':=' 라는 할당 연산자를 사용하지 않고, '=' 를 사용합니다.
제6 장 제어구조
이번 장에서 배울 내용은 제어 구조입니다. 제어 구조는 나열되어 있는 여러 개의 실행 경로 중 하나를 선택하거나, 특정한 문장의 그룹을 반복되게 실행하는 것을 말합니다. 제어 구조를 익히게 되면 여러분들이 프로그램을 구미에 맞게 조종할 수가 있습니다. 원래 프로그램은 명령문이 정의된 순서대로 실행되는 것이 기본 흐름이지만, 제어 구조를 이용하면 프로그램 흐름의 변화를 줄 수 있고, 따라서 효과적인 프로그램을 설계할 수 있습니다.
< 학습목표 >
- 복합문의 구조에 대해 설명할 수 있습니다.
- 선택문의 여러 가지 형태와 쓰임새를 설명할 수 있습니다.
- 반복문의 구조와 의미에 대해 말할 수 있습니다.
< 학습내용 >
- 복합문
- 선택문
- 반복문
1. 복합문
복합문은 문의 집합체를 가리킵니다. 복합문은 다음 절에서부터 소개될 다른 문에 비해 특별히 프로그램의 흐름을 변화시키는 것은 아니고, 한 가지 작업을 행하는 문장들을 모아 하나의 단일체로 엮은 것이라고 생각하시면 됩니다. PASCAL 에서의 복합문의 형태는 다음과 같습니다.
begin
statement_1;
…
statement_n
end
일부 언어에서는 복합문 앞에 변수 선언을 덧붙여 이를 블록으로 사용합니다.
C/C++ 에서는 위의 begin-end 대신 중괄호({}) 를 사용하여 복합문이나 블록의 경계를 나타냅니다.
2. 선택문
선택문은 하나 이상의 실행 경로 중 한 가지를 택할 수 있게 해주는 문의 구조입니다. 선택문은 선택 가능한 범위와 선택할 수 있는 가지 수에 따라서 몇 가지로 분류됩니다.
(1) 양자 택일 선택문 (Two-Way Selection)
대부분의 언어는 양자 택일 선택문을 제공하지만, FORTRAN 과 BASIC 은 다음과 같은 단일 선택문을 제공합니다.
if (condition) then statement
위의 제어 구조는 'condition'이 참일 경우 'statement'를 실행하고 , 거짓이면 'statement'를 실행하지 않습니다 .
양자 택일 선택문은 조건의 참, 거짓에 따라서 실행 경로를 선택하는 문으로 다음과 같은 구조를 갖고 있습니다.
if (condition) then statement_1 else statement _2
위의 경우는 'condition'이 참일 경우 'statement_1'을 수행하고 , 거짓이면 'statement_2'를 수행합니다 .
또한 위와 같은 제어 구조가 여러 겹으로 표현되는 선택문의 형태도 가능합니다.
if (sum == 0) then
if (avg == 0) then
result = 0;
else
result = 0;
그러나 위의 경우에서는 'else' 가 어느 'if' 와 한 쌍인지에 대한 모호성이 발생할 수 있습니다. 통상적인 규칙에 의하면, 'else' 는 가장 가까운 'if' 와 한 쌍으로 간주됩니다. 그러나, 이러한 모호성을 없애기 위해여 복합문의 형태를 이용하기도 합니다. 즉, 문을 의미에 따라서 구조화 하는 것입니다. 위의 예제를 복합문의 형태를 이용하여 표현하면 다음과 같습니다.
if (sum == 0) then
{
if (avg == 0) then
result = 0;
else
result = 0;
}
(2) 다중 선택문 (Multiple-Way Selection)
다중 선택문은 몇 개의 문장이나 문장의 그룹들 가운데 조건에 맞는 실행 경로 하나를 선택할 수 있게 하는 문입니다.
앞 절에서 배운 if-then-else 문장의 확장된 형태를 사용하여 표현할 수도 있고, 다중 선택의 의미를 가진 코드에 의해 표현할 수도 있습니다.
< 예시 1>
다음은 다중 선택문을 표현하기 위해 최근 프로그래밍 언어들이 제공하는 'case' 문 구조 중에서 PASCAL 의 예입니다. 다음 예제는 정수를 표현하는 BNF 입니다.
case expression of
constant_list_1 : statement_1;
…
constant_list_n : statement_n
end
위의 제어 구조에서는 'expression'의 결과 값에 따라 그 값에 맞는 'constant_list'를 찾아서 그에 해당하는 'statement'를 실행하게 됩니다 .
< 예시 2 >
C/C++ 에서는 'switch' 문 구조를 이용해서 다중 선택문을 표현합니다. 예를 들면,
switch (expression) {
case constant_list_1 : statement_1;
…
case constant_list_n : statement_n
[default : statement_n+1;]
}
과 같이 표현합니다. 위의 예제의 의미는 앞서 예제로 보여 드렸던 PASCAL 의 'case' 문과 동일한 의미를 갖습니다. 단 마지막 줄에 대괄호([]) 안에 표현된 문장은 위의 다중 선택문 중 'expression' 의 값에 맞는 'constant_list' 가 없는 경우에 디폴트로 실행하는 문장을 표현한 것으로 이 'default' 문은 다중 선택 구조에 넣어도 되고 넣지 않아도 되는 선택 사양입니다.
또한 C/C++ 에서는 'case' 문의 맨 끝에 'break' 라는 문장을 삽입함으로써 선택이 이루어지면 곧 선택 구조를 빠져나가게 할 수 있습니다.
switch (index) {
case 1 :
case 3 : odd = odd + 1;
sumodd = sumodd + index;
break ;
case 2 :
case 4 : even = even + 1;
sumeven = sumeven + index;
break ;
default : printf("Error in switch!!!");
}
위의 예제는 'index' 가 1 이나 3 일 경우와 'index' 가 2 나 4 일 경우에 그에 해당하는 명령문을 수행하라는 의미를 갖고 있습니다. 또한 'index' 가 1, 2, 3, 4 중 그 어느 것에도 해당하지 않을 때에는 디폴트로 오류를 알리는 문장을 출력하라고 되어 있습니다.
< 예시 3 >
if-then-else 의 확장된 형태로 다중 선택을 하는 방법은 다음과 같습니다.
if (condition_1)then
statement_1;
else if (condition_2) then
statement_2;
…
else if (condition_n)then
statement_n;
else
statement_default;
3. 반복문
반복문은 하나 이상의 문장을 0 번 이상 반복 실행하는 제어 구조를 가진 문으로, 반복 횟수는 유한해야 합니다. 보통 이러한 반복 구조를 루프(Loop) 라고도 부릅니다.
만약 반복 횟수가 무한하다면 무한 루프가 되어 프로그램이 종료되지 않으므로 오류가 일어나게 됩니다.
반복문의 반복 실행은 반복 횟수나 실행을 결정짓는 조건의 참, 거짓에 따라 이루어집니다.
(1) 반복 횟수 기반 (Counter-Controlled) 반복문
반복 횟수 기반 반복문은 루프 변수라고 하는, 반복 횟수를 나타내는 변수를 갖고 있으며 이 변수의 값만큼 실행을 반복하는 구조를 갖습니다.
다음은 C/C++에서의 'for' 문 구조를 나타낸 것입니다 .
for (expression_1;expression_2;expression_3)
statements;
여기에서
- 'expression_1'은 루프 변수의 초기값 ,
- 'expression_2'는 루프 변수의 실행 조건 ,
- 'expression_3'은 루프 변수의 증감 변화량
을 나타냅니다.
위의 구조를 이용해서 구체적인 예를 들어 봅시다.
for (index=0;index<=10;index++)
sum = sum + list[index];
위의 예제는 'index' 가 0 부터 시작해서 10 보다 작거나 같을 때까지 그 값을 하나씩 증가시키면서 실행 코드인 'sum = sum + list[index];' 를 반복 수행하라는 것입니다. 즉, 11 번 동안 다음과 같은 코드를 수행하게 됩니다.
sum = sum + list[0];
sum = sum + list[1];
…
sum = sum + list[10];
(2) 논리 기반 (Logically Controlled) 반복문
논리 기반 반복문은 루프 조건이라는 논리식을 근거로 하는 반복문으로, 이 논리식이 참인 동안 실행을 반복하는 구조를 갖습니다.
< 예시 1>
다음은 논리 기반 반복 구조인 C/C++ 에서의 'while' 문 구조를 나타낸 것입니다.
while (condition)
statement;
위의 제어 구조는 'while'의 사전적 의미 그대로 , 괄호 안의 'condition'이 참인 동안 'statement'를 반복 수행하게 되는데 , 반복 횟수는 0번 이상이 됩니다 .
< 예시 2 >
논리 기반 반복문이면서 , 반복 횟수가 1번 이상인 'do-while' 문 구조가 있습니다 . 다음은 'do-while'문의 구조입니다 .
do
statement;
while(condition)
위의 예제는 일단 'statement'를 수행한 후에 , 'condition'의 참 , 거짓에 따라 'statement'의 반복 여부를 결정합니다
< 예시 3 >
'do-while' 문과 같은 의미를 갖는 PASCAL의 논리 기반 반복문인 'repeat-until' 문 구조가 있습니다 . 'repeat-until'문 구조의 예는 다음과 같습니다 .
repeat
sum = sum + count;
count = count + 1;
until (condition<=10)
위의 예제는 일단 'sum' 과 'count' 의 값을 변화시킨 뒤, 'count' 가 10 보다 작거나 같으면 명령문을 반복하고, 10 보다 크면 루프를 빠져 나오도록 하는 의미를 갖고 있습니다.
< 정리해봅시다 >
제 6 장 제어 구조를 모두 배우셨습니다. 제어 구조는 특별한 예약어( 혹은 키워드) 를 익혀 문 단위로 프로그램의 흐름을 제어할 수 있습니다. 그래서 제어 구조는 강의 자료의 절 제목처럼 선택문, 반복문 이라고 하지 않고, 예약어의 이름을 따서 보통 'if' 문, 'for' 문, 'while' 문 이라고 부릅니다. 내용을 간단하게 정리해보겠습니다.
의미 있는 작업을 하기 위한 문장들을 모아 놓은 것입니다. 보통 프로그램의 시작이나 끝을 알리는 'begin-end', 중괄호({}) 로 묶여진 문장의 그룹이 복합문이 됩니다.
하나 혹은 그 이상의 경우의 수에 대하여 조건에 맞는 명령문을 골라 실행할 수 있게 해 주는 제어구조입니다. 선택문의 종류에는 단일 선택문, 양자 택일 선택문, 다중 선택문이 있습니다.
- 단일 선택이나 양자 택일 선택은 'if-then-else'문을 ,
- 다중 선택은 'case'문과 'switch'문 , 그리고 'else if'문을 사용합니다 .
프로그램 상에서 조건에 따라 반복 수행해야 하는 명령문이 있을 때 사용하는 제어구조입니다.
- 반복 횟수에 의한 반복문에는 'for'문 ,
- 논리 구조에 의한 반복문에는 'while'문 , 'do-while'문 , 'repeat-until'문 등이 있습니다 .
< 연습문제 >
1. 반복문 중 'while'문과 'do-while'문의 차이점은 무엇일까요 ?
'while' 문은 0 번 이상 명령문 반복을 수행하고, 'do-while' 문은 1 번 이상 명령문 반복을 수행합니다. 따라서, 명령문을 적어도 한 번은 수행해야 하는 경우에는 'do-while' 문을 사용합니다.
2. 다음 중 다중 선택을 의미하는 구조로 이루어진 코드가 아닌 것은 무엇일까요?
①
switch (number)
{
case 1 : sum = sum + 1;
case 2 : sum = sum * 2 + 1;
default : sum = sum + 2;
}
②
if (x < y)
{
temp = x;
x = y;
}
③
case mark of
'A' : grade = 4.3;
'B' : grade = 3.3;
'C' : grade = 2.3
end
④
if (month == 1) then
days = 31;
else if (month == 2) then
days = 28;
else if (month == 3) then
days = 31;
else if (month == 4) then
days = 30
답은 ②번 입니다.
7 장 부프로그램
은행 계좌 관리 프로그램 의뢰를 받았습니다. 은행 계좌 관리 프로그램에서 해야 할 일들은 잔고 관리와 이자 계산, 대출 관리 등이 있다고 합니다. 만약 프로그램을 의뢰 받은 사람이 여러분이라면 어떻게 프로그램을 작성하시겠습니까?
보통은 잔고 관리하는 함수, 이자 계산 함수, 대출 관리 함수를 따로따로 만들어 이것들을 하나로 모아 전체 프로그램을 구성할 것입니다. 이렇게 프로그램을 작성하는 것이 효율적일 뿐만 아니라 나중에 프로그램을 유지보수 할 때 그 작업이 용이할 것입니다.
이번 장에서는 이러한 부프로그램들에 대한 개념을 배우려고 합니다. 부프로그램의 형식과 의미, 기능 그리고 부프로그램의 수행 과정 등을 살펴 보겠습니다.
< 학습목표 >
- 부프로그램이 전체 프로그램 구조 안에서 어떻게 사용되는지 말할 수 있습니다.
- 부프로그램이 제공하는 특수한 기능들을 사용하실 수 있습니다.
< 학습내용 >
- 부프로그램의 소개
- 매개변수 전달기법
- 부프로그램의 기억 장소 할당
- 부프로그램의 부가적 기능들
1. 부프로그램 소개
(1) 부프로그램이란 ?
일반 명령형 프로그래밍에서는 언어에서 제공하는 기본 명령어의 나열로 문제를 해결하는데 비하여, 부프로그래밍 방식은 기본 명령어들의 조합으로 된 사용자 함수를 정의하여 문제를 해결하는 프로그래밍 방식입니다.
일반적인 고급 프로그래밍 언어에서는 프로그램을 모듈화시키는 기법으로 함수와 서브루틴 또는 프로시저의 형태로 부프로그램을 지원합니다.
다음은 부프로그램을 이용하여 프로그램을 작성했을 때, 프로그램이 실행되는 방식을 그림으로 나타낸 것입니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_03_g01.gif" \* MERGEFORMATINET
위 그림과 같이 어떤 프로그램이 명령어를 순차적으로 수행하다가 함수 호출( 부프로그램을 실행시키기 위한 명시적 요구 방법) 명령어를 만나면, 호출한 함수로 가서 그 함수를 모두 실행한 후 다시 원래 프로그램으로 돌아와서 나머지 명령어를 수행하게 됩니다.
부프로그램의 헤더(Header) 는 다음과 같이 표현되는데, 이 헤더에는 부프로그램의 종류, 이름, 그리고 부프로그램에 필요한 매개변수 목록의 세 가지 정보를 제공합니다.
procedure adder (paramter_list)
function adder (parameter_list)
그러나 C/C++ 언어에서는 부프로그램으로서 오직 함수만 제공하기 때문에 위와 같은 부프로그램의 종류를 따로 명시해 주지는 않습니다.
(2) 매개변수 (Parameters)
매개변수는 부프로그램이 자료에 접근하는 방법으로 사용되는 것입니다. 그러나 이것을 어렵게 이해할 필요는 없습니다. 여러분이 수학시간에 배웠던 함수를 생각해 보세요. 함수 f(x) 에서 'x' 를 매개변수라고 했던 것을 기억하실 겁니다. 이와 같이 부프로그램은 자신의 작업을 수행하는데 어떤 자료가 필요하면 매개변수를 이용해서 자료에 접근합니다. 바꾸어 말하면, 작업 수행에 자료가 전혀 필요하지 않다면 매개변수가 없어도 된다는 말이죠.
매개변수는 'XX 매개변수' 처럼 이름이 있지만 여러분은 이 이름들에 너무 신경 쓰실 필요는 없습니다. 가장 중요한 것은 매개변수를 올바로 사용하는 것이니까요. 이 절에서도 두 가지 매개변수의 종류에 대해서만 언급을 하려고 합니다.
형식 매개변수 (Formal Parameter)
호출된 부프로그램이 넘겨받는 변수로서 부프로그램의 헤더에 있는 매개변수를 일컫습니다. 즉, 부프로그램의 정의부에 나타난 매개변수를 말합니다.
procedure example(a : integer; b : real);
실 매개변수 (Actual Parameter)
호출하는 명령문에서 넘겨주는 변수로서, 부프로그램 호출 명령문에 포함된 매개변수 목록을 가리킵니다. 즉, 메인 프로그램에서 부프로그램을 호출할 때, 호출 명령문에 나타난 매개변수를 말합니다.
example(10, 15.5);
단, 부프로그램의 형식 매개변수와 실 매개변수의 개수는 반드시 일치해야 한다는 것을 꼭 기억하시기 바랍니다.
(3) 프로시저 (Procedure) 와 함수 (Function)
프로시저와 함수는 둘 다 부프로그램입니다. 다만 프로시저와 함수의 차이는, 프로시저는 프로시저의 이름으로 값을 반환할 수 없지만 함수는 함수 자신의 이름으로 하나의 값을 반환할 수 있습니다. 또한 FORTRAN 에서의 프로시저를 서브루틴이라고 합니다. 프로시저나 함수의 구조는 다음과 같습니다.
procedure(혹은 function) procedure_name(parameter_list)
declaration part
body part
대개의 언어에서는 함수와 프로시저를 동시에 제공하지만, C/C++ 언어에서는 함수만을 지원합니다. 따라서 결과값을 반환하지 않는 프로시저의 기능을 대체하기 위해 'void' 라는 자료형을 사용하고, 다음과 같은 코드로 나타낼 수 있습니다.
void non_return_value (void) {
…
}
2. 매개변수 전달기법
매개변수 전달이란, 정의된 부프로그램을 호출하는 과정에서 부프로그램 호출 명령문으로부터 정의된 부프로그램 간의 변수 자료값을 전달하는 것을 의미합니다. 부프로그램 내에서 사용되는 변수는 3 가지가 있는데, 각각 다음과 같습니다.
- 형식 매개변수
- 지역 변수
- 비지역 변수( 전역 변수)
지역변수와 비지역 변수( 전역 변수) 에 대한 내용은 3 장에서 배우셨으므로 잘 알고 계시리라고 생각됩니다. 그렇다면 이 장에서 새롭게 등장한 것이 바로 형식 매개변수인데, 메인 프로그램에서 사용되던 변수가 부프로그램으로 전달될 때 매개변수라는 것을 사용합니다.
매개변수는 어떤 방법으로 전달될까요? 대표적인 매개변수 전달기법에는 크게 다음과 같은 것들이 있습니다.
- 값에 의한 전달기법 (Pass-By-Value)
- 참조에 의한 전달기법 (Pass-By-Reference)
(1) 값에 의한 전달기법
값에 의한 전달기법은 실 매개변수가 그것과 일치하는 형식 매개변수를 초기화하는데 사용되며, 이 형식 매개변수는 지역 변수처럼 작용하는 기법입니다.
다음 예를 들어봅시다.
void swap (int a, int b) {
int temp = a;
a = b;
b = temp;
}
위 함수는 두 개의 값을 서로 교환하는 함수입니다. 위의 함수를 실행하기 위해 다음과 같은 호출 명령을 실행하면
swap(c, d);
c, d 의 값은 변하지 않습니다. 왜냐하면 위 함수에서의 매개변수 a, b 는 위 함수에서 지역변수처럼 사용되었기 때문에 위 함수를 벗어나면 그 효력이 없어지기 때문입니다. 따라서 호출 명령으로 c, d 의 값을 바꾸려 해도 함수를 수행하고 나면 실 매개변수인 c, d 는 아무런 영향도 받지 않게 되는 것입니다.
(2) 참조에 의한 전달기법
호출하는 프로그램이 호출되는 부프로그램에게 실 매개변수의 주소를 전달하는 기법입니다. 따라서 호출되는 부프로그램은 호출하는 프로그램의 실 매개변수에 접근할 수 있고 공유할 수도 있습니다. 실 매개변수에 의해 전달된 변수는 부프로그램에 의해 직접 수정이 가능합니다.
앞 장에서와 같은 예를 들어 봅시다.
void swap (int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
과연 이 함수를 가지고 다음 호출 명령문을 어떤 결과가 나올까요?
결론부터 말씀 드리면, 이 경우에는 c 와 d 의 값이 서로 바뀝니다.
swap(&c, &d);
이번 예제가 앞 장에서의 예제와 다른 점은 형식 매개변수가 포인터로 선언되었다는 것입니다. 포인터는 변수의 저장 장소인 메모리 주소와 그 변수의 값을 함께 표현하는 자료형이라는 것, 4 장에서 배운 내용 기억하시지요?
위의 호출 명령문을 보면, 실 매개변수로 c 와 d 의 메모리 주소값을 넣었습니다. 이 주소값을 받아서 'swap' 함수는 각각의 변수가 가리키던 메모리 공간의 위치를 바꿉니다.
이를 그림으로 표현하면 다음과 같습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_08_g01.gif" \* MERGEFORMATINET
3. 부프로그램의 기억장소 할당
일단 부프로그램을 호출하면 부프로그램이 실행됩니다. 이것을 다른 표현으로 활성화되었다라고 합니다. 부프로그램이 활성화되면 이것의 정보를 담을 만한 공간이 필요합니다.
여기서 공간이란, 부프로그램의 호출과 반환 시 부프로그램을 호출하는 프로그램의 상태는 어떤지, 매개변수는 어떻게 되는지, 부프로그램의 실행이 끝나면 돌아가야 할 주소는 어디인지 등을 담을 만한 공간을 의미합니다.
이러한 공간을 활성화 레코드 (Activation Record)라고 합니다 . 또한 활성화 레코드로 표현된 자료들의 집합체를 활성화 레코드 실체 (Activation Record Instance)라고 하며 , 줄여서 'ARI'라고 표현합니다 . 활성화 레코드의 구조는 다음 그림과 같습니다 .
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_09_g01.gif" \* MERGEFORMATINET
위 그림에서 동적 링크(Dynamic Link) 와 정적 링크(Static Link) 가 어떤 것인지 궁금해 하시는 분들이 많으시리라고 생각됩니다. 동적 링크는 부프로그램을 호출한 프로그램의 'ARI' 를 가리키고, 정적 링크는 현재 부프로그램을 포함하는 상위 부프로그램의 'ARI' 를 가리킵니다.
프로그램 예제
자, 그럼 이제 예제를 통하여 부프로그램의 기억 장소가 어떻게 할당되는지 알아 봅시다.
다음과 같은 프로그램이 있다고 합시다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_10_g02.gif" \* MERGEFORMATINET
이 프로그램의 호출 구조는 다음과 같습니다.
* main은 B를 호출 , B는 A를 호출 , A는 C를 호출 .
이 때 활성화 레코드의 변화는 다음 그림과 같습니다. 단 실선은 동적 링크를, 점선은 정적 링크를 나타냅니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_10_g01.gif" \* MERGEFORMATINET
4. 부프로그램의 부가적 기능들
일부 프로그래밍 언어에서는 부프로그램에 다중 기능을 부여하고 있습니다.
(1) 중복 부프로그램 (Overloaded Subprograms)
중복 부프로그램이란, 서로 다른 부프로그램이 같은 이름을 갖고 있을 때를 말합니다. 보통 부프로그램이 수행하는 기능은 같고, 단지 매개변수에 차이가 있을 뿐입니다. 중복 부프로그램은 ADA 와 C++ 에서 제공됩니다.
Average(int a, int b); (1)
Average(int x, int y, int z); (2)
위의 예제는 같은 이름을 갖는 함수의 프로토타입을 선언한 것입니다. 위와 같이 'Average' 함수는 전달된 매개변수들의 평균값을 구하는 것이라고 합시다. 단, (1) 은 두 정수의 평균을, (2) 는 세 정수의 평균을 구하는 함수입니다. 그러나 함수의 이름이 같더라도 매개변수의 개수나 형이 다르면 컴파일 시 컴파일러가 알아서 서로 다른 함수로 취급합니다.
(2) 다형 부프로그램 (Polymorphic Subprograms)
다형 부프로그램이란, 프로그램 수행 시마다 서로 다른 자료형의 매개변수를 사용할 수 있는 부프로그램을 말합니다. 이는 C++ 에서 제공합니다.
templete <class Type>
Type max ( Type first, Type second) {
max = first > second ? first : second;
}
위 코드는 두 개의 매개변수를 전달 받아 큰 값을 찾아내는 함수입니다. C++ 에서는 'templete' 이라는 키워드를 이용하여 서로 다른 자료형으로도 하나의 함수를 호출할 수 있게 해 줍니다.
즉 다음과 같은 호출문이 모두 가능합니다.
int a, b; char c, d; max (a, b); max (c, d);
< >
제 7 장 부프로그래밍을 모두 배우셨습니다.
다음 사항을 반드시 숙지하세요!
프로그램 모듈화 작업을 가능하게 해 주는 프로그래밍 기법으로, 하나의 프로그램을 기능별로 나누어서 그 기능을 수행하는 부프로그램을 만들 수 있습니다. 마치 작업 분담 같은 것이지요.
언어에서 제공하는 부프로그램으로는 프로시저와 함수가 있습니다.
부프로그램만의 작업을 수행하기 위해 외부로부터 자료를 받아야 하는 경우가 생기는데, 이 때 외부의 자료를 받아 쓰기 위해 사용하는 것이 매개변수입니다. 매개변수 전달 기법에는 값에 의한 전달과 참조에 의한 전달이 있었습니다.
수행되면 부프로그램의 저장 장소가 할당되어야 하는데, 이 때 사용하는 것이 활성화 레코드입니다. 활성화 레코드는 부프로그램의 지역 변수, 매개변수를 저장할 수 있는 공간과 부프로그램간의 호출 관계와 계층 구조를 나타내는 동적 링크와 정적 링크, 그리고 부프로그램 수행이 끝나면 돌아가야 할 반환 주소로 이루어져 있습니다.
밖에 프로그래밍 언어가 고급화될수록 제공하는 기능들이 많은데, 중복 부프로그램 및 다형 부프로그램이 그것입니다.
< 연습문제 >
1. 프로시저와 함수의 차이는 무엇일까요?
프로시저는 프로시저의 이름으로 값을 반환할 수 없지만, 함수는 함수 자신의 이름으로 하나의 값을 반환할 수 있습니다.
2. 매개변수 전달 기법에는 무엇이 있는지 말해보세요.
값에 의한 전달, 참조에 의한 전달
3. 활성 레코드의 구조를 그려 보세요.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/07/img/pl07_09_g01.gif" \* MERGEFORMATINET
제8 장 추상자료형
여러분이 일상 생활에서 사용하는 각종 전자 제품들이 어떤 원리에 의해서 작동하는 것인지 생각해 보신 적이 있으신지요. 버튼만 누르면 알아서 사진을 찍어주는 자동 카메라는 속에서 어떤 작동을 일으키는지에 상세하게 알고 계신 분은 극히 드물 것입니다. 대개는 사용 설명서를 보고 어떻게 하면 사진이 찍히고, 어떻게 하면 줌(Zoom) 이 작동되는지에 대해서만 알고 계시지요. 이 때, 카메라에 해당하는 것이 추상 자료형이고, 카메라의 기능에 해당하는 것이 추상 자료형이 수행하는 연산들입니다. 이미 우리가 배운 기본 자료형도 일종의 추상 자료형이라고 할 수 있습니다. 4 장에서 배운 문자형의 경우, 여러분이 문자형 변수를 선언하고 그 변수에 문자값( 알파벳) 을 할당하면, 실제 컴퓨터에서는 문자가 ASCII 코드로 변환되어 프로그램을 수행하지만, 여러분은 일일이 그러한 작업을 하지 않아도 컴퓨터가 내부적으로 알아서 다 처리해 주니까요.
이번 장에서는 이러한 추상 자료형의 개념을 배우고, 이를 기초로 사용자 정의 추상 자료형을 직접 구현해 볼 것입니다
< 학습목표 >
- 추상화와 캡슐화에 대한 개념을 설명할 수 있습니다.
- 추상화와 캡슐화 작업을 통해 생겨난 추상 자료형의 구조와 의미를 익히고 스스로 추상 자료형을 정의하고 구현할 수 있습니다.
< 학습내용 >
- 추상화의 개념
- 캡슐화의 개념
- 추상 자료형
1. 추상화의 개념
추상화란 속성(Attribute) 의 일부만으로도 어떤 과정이나 객체를 표현할 수 있는 것을 의미합니다. 추상화라고 하면 대개 애매모호하게 만드는 작업으로 오해하기 쉽지만, 프로그래밍에서의 추상화는 프로그램의 복잡성을 감추고 프로그래밍 과정을 단순화하기 위한 작업을 말합니다.
이는 프로그래머에게 중요한 속성에 대해서만 몰두할 수 있게 하고, 중요하지 않은 속성에 까지 세심한 주의를 기울이지 않아도 되도록 지원합니다.
추상화에는 프로세스 추상화와 자료 추상화가 있는데, 후자에 대해서는 뒷 페이지에서 자세히 배우기로 하고, 여기서는 프로세스 추상화에 대해서 간략하게 설명하겠습니다.
프로세스 추상화란 프로그램을 작성하는 형식에 관한 추상화입니다. 프로그램을 짤 때 한꺼번에 뭉쳐서 짜는 것이 아니라 프로그램이 수행해야 하는 작업을 기능별로 구분해서 모듈화 하게 되면 나중에 프로그램을 수정하거나 유지? 보수 해야 할 때 좀 더 수월하겠죠?
빗대어서 설명해 볼까요? 여러분은 혹시 컴퓨터 속을 들여다 보신 적이 있습니까? 그 속을 들여다보면 여러 가지 장치 - 하드 디스크, 플로피 디스크, 메모리, 모뎀, 메인 보드 등 - 들로 구성되어 있습니다. 하드 디스크는 저장 장치이고, 모뎀은 통신을 위한 장치입니다. 이러한 장치 하나하나는 또다시 수십, 수백개의 부품들로 이루어져 있지요. 이렇게 수행하는 기능마다 하나의 장치를 만드는 작업이 모듈화의 의미와 같다고 할 수 있습니다. 또한 여러 가지 장치들로 조립된 컴퓨터는 깔끔한 케이스로 쌓여 여러분에게 공급되고, 여러분은 특별히 그러한 장치들을 뜯어 부수거나 개조하지 않고 컴퓨터가 제공하는 기능들을 잘 이용하면 되는 것입니다. 이것이 추상화의 의미지요. 하지만 여러분은 장치들이 혹은 부품들이 어떻게 상호 작동해서 컴퓨터가 제 기능을 수행하는지는 알 수 없고, 사실 알 필요도 없습니다.
프로그래밍에서의 예를 들면, 함수나 프로시저 같은 부프로그램이 바로 프로세스 추상화라고 할 수 있습니다. 수행해야 하는 작업별로 함수나 프로시저를 만들면, 전체적인 프로그램에서 부프로그램이 내부적으로 어떤 일을 하는지 알 필요 없이 부프로그램을 실행시키는 호출 명령문을 이용해 작업을 수행할 수 있습니다. 또한, 호출 명령문만 봐도, ' 아, 이 줄에서는 이런 작업을 수행하는 구나' 라고 알 수가 있지요.
이러한 한 줄의 호출 명령문만으로도 이 부프로그램이 무슨 작업을 수행하는 부프로그램인지 알 수 있으려면, 변수 이름, 부프로그램 이름, 매개변수 이름 등이 프로그램 작업 내용을 의미있게 잘 나타내어야 할 것입니다. 예를 들어, 다음과 같은 호출 명령문 을 보시고, 함수의 이름, 매개변수 이름 등을 근거로 해서 이 함수가 어떤 작업을 수행하는 함수일 것이다라는 것을 유추해 보십시오.
sort_integer(list, list_length);
답은 여기에 있습니다 .
이 함수는 정수를 정렬하는 것입니다. 함수 이름으로부터 유추할 수 있었지요? 그리고, 매개변수를 보면 'list' 와 'list_length' 가 있는데, 전자는 정수 목록, 후자는 그 목록의 길이일 것이라고 생각하셨을겁니다. 그렇다면 이 함수는 정확히 'list_length' 길이를 갖는 'list' 라는 정수들의 목록을 받아서 정렬하는 함수다라는 유추가 가능하겠지요? 단, 이것이 큰 숫자부터 정렬하는 것인지 작은 숫자부터 정렬하는 것인지는 알 수가 없습니다. 이러한 의미까지 표현해 주고 싶으면 함수 이름을 increasing_sort_integer 혹은 decresing_sort_integer 라고 해주면 의미전달이 더 확실해지겠지요
2. 캡슐화의 개념
여기에서는 다음 페이지에서 다룰 자료 추상화를 배우기 전에 캡슐화의 의미만을 간단히 정리하려고 합니다. 캡슐화란, 프로그래밍 언어에서 데이터 또는 함수와 프로시저 등과 같은 부프로그램에 대한 내부 구조는 알려주지 않고, 이러한 정보를 이용하는 인터페이스만을 제공하여 이용하도록 하는 프로그래밍 기법을 말합니다.
캡슐화는 다음과 같은 그림으로 표현할 수 있습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/08/img/pl08_05_g01.gif" \* MERGEFORMATINET
3. 추상자료형의 소개
추상 자료형이란, 자료형의 표현과 그에 관련된 연산들을 제공하는 부프로그램을 함께 묶어 캡슐화한 것을 말합니다. 단, 추상 자료형과 캡슐화의 차이가 있다면, 추상 자료형은 하나의 자료형이지만 캡슐화는 자료형이 아니라는 것입니다.
추상 자료형을 사용하면, 자료를 수행될 연산과 함께 선언할 수 있고, 정보 은닉(Information Hiding) 개념을 도입하여 프로그램을 읽기 쉽게 하고 유지/ 보수를 용이하게 할 수 있습니다.
예를 들어 고급 프로그래밍 언어에서 제공하는 실수형은 정보 은닉이라는 자료 추상화의 개념을 갖고 있습니다. 실제 여러분은 메모리 셀에 담긴 실수형 자료값의 형식(Format) 은 알 수 없고, 또 시스템이 제공하는 실수형 연산 외에 새로운 연산을 만들 수도 없지요. 사용자 정의 추상 자료형도 마찬가지입니다.
사용자 정의 추상 자료형은 프로그램 내에서 이 자료형의 변수를 선언할 수 있도록 하지만, 이러한 변수의 설명이나 추상 자료형에서 제공하는 연산들에 대한 설명은 감춥니다. 그냥 추상 자료형을 만든 사람이 자료형 정의에서 제공한 연산들만 사용할 수 있을 뿐입니다.
추상 자료형의 의미가 어렵다고 느끼시는 분들이 많을 것이라 생각되지만, 앞에서 배운 추상화와 캡슐화에 대한 의미를 다시 한번 상기하시고, 이 부분을 이해하시기 바랍니다. 또한 다음 절에서는 C++ 에서 제공하는 추상 자료형에 대해서 배울 것이므로 전체적인 의미만 확실하게 짚고 넘어가시길 바랍니다.
4. C++ 의 ‘CLASS’
추상 자료형을 제공하는 언어가 몇 가지 있지만, 이 강좌에서는 C++ 의 예를 들어 설명하도록 하겠습니다.
C++ 에서는 추상 자료형을 제공하는데, 이것을 'class' 라고 부릅니다. 예제를 통해서, 'class' 에 대한 개념도 익히고 여기서 나오는 용어들도 간단히 정의해 보도록 하겠습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/08/img/pl08_07_g01.gif" \* MERGEFORMATINET
예제 프로그램이 너무 길어서 여러분께서 페이지를 상하로 움직이면서 강좌를 보시기에 힘드시겠지만, 그래도 포기하지 마시고 예제를 통해 새로운 것을 하나하나 익혀 나가시길 바랍니다. 일단 프로그램을 전체적으로 훑어 보시기 바랍니다. 번호 매긴 순서대로 차근히 설명해 나가도록 하겠습니다.
(1) 에 보시면, 굵직한 이탤릭체로 'class' 라고 쓰여있지요? 이것이 'class' , 곧 추상 자료형을 정의하는 곳입니다. 'class' 이하 중괄호로 싸여진 블록 안에 함수 프로토타입(prototype) 과 정수형 변수가 있습니다. 이것을 각각 멤버 함수, 멤버 변수라고 합니다. 여기서 멤버는 'class' 를 이루는 구성 요소를 가리킵니다. 그 구성 요소가 함수이면 멤버 함수, 변수이면 멤버 변수가 되는 것입니다.
그런데 (2) 와 (3) 에 각각 'public' 과 'private' 라는 키워드가 있지요? 'public' 은 외부의 접근을 허용하는 부분으로, 다른 사람들 눈에 보여도 되는 부분입니다. 'private' 는 외부의 접근을 막아 놓아 자료를 은폐하는데 쓰이는 키워드입니다. 보통 자료 항목( 멤버 변수 선언부) 은 'private' 로 선언하고, 멤버 함수의 경우는 'public' 으로 선언합니다. 멤버 함수를 'public' 으로 선언하는 이유는, 만약 그렇지 않으면 프로그램에서 이러한 멤버 함수들을 호출할 수 없기 때문입니다. 물론 멤버 함수를 'private' 로 선언할 수도 있지만, 이 경우에는 프로그램에서 호출할 수가 없습니다.
(4) 에는 추상 자료형인 'DayOfYear' 형 변수를 선언한 곳입니다. 'DayOfYear' 형으로 선언된 변수는 'class' 에서 정의된 두 개의 자료 항목과 다섯 개의 자료 연산자( 즉, 함수) 들의 특성과 기능을 모두 갖게 됩니다.
(5), (6), (7) 은 멤버 함수를 호출한 부분입니다. 그리고, (8) 이하는 멤버 함수 정의 부분으로 멤버 함수를 정의할 때에는 '::' 기호를 이용하고, 각 함수마다 수행해야 할 기능들은 중괄호 안에 나타냅니다. 이처럼, 멤버 함수가 내부적으로 어떻게 수행되는지 알지 못하더라도, (5), (6), (7) 처럼 호출해서 사용하면 그에 해당하는 함수들은 자신만의 명령문을 알아서 수행합니다.
(9) 에서는 'private' 로 선언된 멤버 변수인 'month' 와 'day' 가 사용되고 있는 부분인데요, 'private' 로 선언된 멤버 변수들은 프로그램, 즉 메인 프로그램에는 나타나지 않고, 멤버 함수 속에서만 사용됩니다. 멤버 함수를 호출해서 사용하기는 하지만 멤버 함수의 내부는 아무도 모르기 때문에, 이와 같이 외부로부터 자료를 은폐하는 'private' 멤버 변수들을 멤버 함수 속에서만 사용하면 아무도 그 변수의 존재를 알지 못하게 됩니다.
< 정리해봅시다 >
제 8 장 추상 자료형을 모두 배우셨습니다.
앞서 배운 내용들을 다시 한번 점검해 보도록 하겠습니다.
복잡한 프로그램을 보기 쉽도록 복잡한 부분은 가리고 꼭 필요한 부분만 드러내 전체적으로 프로그래밍을 세련되고 깔끔하게 하는 작업입니다.
자료 항목과 그에 해당하는 연산과 연산자들을 한데 묶어 놓은 것을 말합니다.
자료형은 자료형의 표현과 그에 관련된 연산들을 제공하는 부프로그램을 함께 묶어 캡슐화한 것을 말하는데, 이 때 추상 자료형에 포함되는 자료형의 표현 혹은 자료 항목을 멤버 변수라고 하고, 부프로그램을 멤버 함수하고 합니다.
이러한 멤버 변수나 멤버 함수는 'public' 혹은 'private' 으로 선언되는데,'public' 은 프로그램 내에 보여져야 하는 부분을, 'private' 은 프로그램 내에 감춰도 되는 부분을 선언할 때 사용됩니다.
< 연습문제 >
1. C++ 의 'class' 를 이용하여 다음과 같은 자료 항목과 기능을 가진 추상 자료형을 선언해 보십시오.
< 은행 계좌 관련 추상 자료형 >
a. 멤버 변수
- 원금
- 이율
b. 멤버 함수
- 이자 계산 함수
- 원리 합계 함수
class Account
{
public :
double ComputeInterest();
double Sum_of_Pricipal_Interest();
private :
int pricipal;
double interest_rate;
};
클래스 이름, 멤버 변수 이름이나 멤버 함수 이름은 다를 수 있습니다. 다만 자료형의 구조는 위와 같아야 합니다
제9 장 예외처리
준비성이 철저한 사람들은 한 가지 작업을 하더라도 작업 도중 발생할 수 있는 모든 경우를 예측하고, 이에 대비할 수 있도록 합니다.
프로그램에서도 마찬가지로 프로그램 수행 중에 나타날 수 있는 오류를 미리 예측하여 이를 처리할 수 있는 메커니즘이 있습니다. 이것이 예외 처리입니다.
이번 장에서는 예외 처리에 대한 개념과 예외 처리 메커니즘을 이용한 예제 프로그램을 공부하도록 하겠습니다.
< 학습목표 >
- 예외 처리의 의미를 이해할 수 있습니다.
- 예제 프로그램을 통해서 어떻게 예외 처리가 이루어지는지 알 수 있습니다.
< 학습내용 >
- 예외 처리
- C++에서의 예외 처리
1. 예외처리
대부분의 컴퓨터 하드웨어 시스템들은 소수점 오버플로우(Overflow) 같은 프로그램 수행 오류를 발견할 수 있는 능력이 있습니다. 그리고 프로그래밍 언어들 중에는 사용자 프로그램이 오류를 발견하거나 처리할 수 없는 방향으로 설계되고 구현된 것이 있습니다. 이러한 언어들에서는 오류가 일어나면 단순히 프로그램을 종료하거나 운영 체제에게 제어권을 넘깁니다. 프로그램 수행 오류에 대한 운영 체제의 반응은 컴퓨터 진단 메시지를 띄운 후 프로그램을 종료시키는 것입니다.
그러나 오류에는 하드웨어에 의해 발견되지 못하고 컴파일러에 의해 생성된 코드에 의해서 발견되는 것들이 있습니다. 예를 들어 배열의 하위 영역 같은 것들인데, 이들의 오류는 하드웨어에 의해 거의 발견되지 못하지만 사실은 프로그램 수행 시 치명적인 오류를 범할 수 있습니다.
이런 종류의 오류는 프로그래밍 언어 설계 시 고려되어 프로그래밍 언어 컴파일러가 발견할 수 있게 해야 합니다.
요즘 프로그래밍 언어들은 오류의 하드웨어적 발견과 소프트웨어적 발견이 일어날 때 반응을 취하는 메커니즘을 제공하고 있습니다. 또한 프로그래머로 하여금 예기치 않은 오류 발생에 대비하여, 오류가 발생하면 이것을 처리할 수 있도록 하는 메커니즘을 제공하고 있습니다. 이러한 메커니즘을 총체적으로 예외 처리라고 합니다.
예외 처리는 예외 상황 발생 시 이를 발견하는 과정에서 요구되는 특별한 처리 과정을 말합니다. 그리고 이러한 처리 과정을 담당하는 코드 집합을 예외 처리기(Exception Handler) 라고 합니다.
프로그램 실행 중에 예외적 조건이 발생하면 제어가 내부적으로 예외 처리기에게 넘어가서 예외를 처리한 후, 다시 예외가 발생했던 곳으로 제어가 되돌아 오게 됩니다. 이를 다음과 같은 그림으로 표현할 수 있습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/09/img/pl09_02_g01.gif" \* MERGEFORMATINET
다음 예제 코드를 통해 예외 처리를 어떻게 제어하는지 알아 봅시다.
위의 코드의 (1) 이하를 보시면 예외 처리기 코드가 있습니다. 위 함수는 보시는 바와 같이 평균값을 구하는 함수입니다. 그런데, 만약 'total' 이 0 이라면 위 평균값을 구할 수가 없게 되죠. 왜냐하면, 0 은 제수가 될 수 없기 때문입니다. 이 점을 예외 사항으로 간주하여, 예외 처리할 수 있게 한 것입니다. 그리하여, 위의 예외 처리의 경우, 제수가 0 일 경우에는 평균값을 일단 0 으로 만든 후, 평균을 구할 수 없다라는 메시지를 출력하도록 하고 있습니다.
그리고 예외 처리가 끝나면 다시 원래 프로그램을 순차적으로 수행하게 되는 것입니다.
2. C++ 에서의 예외처리
이 절에서는 C++ 에서 제공하는 예외 처리 메커니즘에 대하여 알아보고, 예제 프로그램을 통해 익혀 보려고 합니다.
예외 처리를 제공하는 언어는 여러 가지가 있지만, C++ 를 선택한 것은( 자료 추상화에서도 마찬가지였지요.) C 기반 언어들이 응용 프로그램을 짜는 가장 보편적인 언어이기 때문입니다. 그럼 본격적인 학습에 들어가도록 하겠습니다.
C++ 에서 제공하는 예외 처리 메커니즘은 'try-catch' 문입니다. 이제까지 예를 통해 여러분이 보셨듯이 프로그래밍 언어에서 제공하는 키워드나 예약어는 모두 일상 언어의 의미를 그대로 살리는 용어들을 사용하고 있습니다. 'try-catch' 문도 마찬가집니다. 단어의 사전적 의미를 그대로, '( 예외가 있는지 없는지) 계속해서 찔러보고 잡아내라' 는 것이지요.
C++의 'try-catch'문의 형식은 다음과 같습니다 .
또한, 예외가 발생하면 이것을 예외 처리기에 넘겨주는 'throw' 키워드가 있습니다. 이 역시 '( 예외를 발견하면 예외 처리기에게) 던져라' 의 뜻이 되지요. 'throw' 키워드는 예외의 시작을 나타내며, 그 뒤에는 예외의 성격을 나타내는 문자열이나 객체와 같은 값이 옵니다.
형식만 보고는 감이 잘 안 잡히시죠? 그럼 예제 프로그램을 다음 페이지에서 보도록 하겠습니다.
프로그램
다음은 조화평균(Harmonic Mean) 을 구하는 프로그램입니다. 여기서, 잠깐 수학시간에 배우셨던 조화평균의 식을 짚고 넘어 가도록 합시다.
두 수 a, b 의 조화평균은 다음과 같습니다.
그런데 여기서 분모인 두 수의 합이 0 인 경우에는 조화평균을 구할 수 있을까요? 구할 수 없겠죠. 따라서 다음과 같은 조화평균을 구하는 프로그램에서는 분모가 0 이 되는 경우를 예외로 잡아 프로그램을 작성하려고 합니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/09/img/pl09_07_g02.gif" \* MERGEFORMATINET
위의 예제 프로그램에서, (1) 의 'try' 블록을 봅시다. 'try' 블록은 예외 상황 발생이 예상되는 코드를 적는 곳입니다. 지금 이 블록에서는 조화평균을 구하는 함수를 예외가 발생할 수도 있는 코드로 지정하고 있습니다.
일단 함수 호출 명령문이 있으므로 함수 'hmean' 을 수행합니다. 만약 분모가 0 이 되지 않는 상황, 즉 이 프로그램에 의하면 'a = -b' 인 상황이 아니라면 함수는 제 기능을 수행하고, 'try' 블록 다음에 나오는 'catch' 블록은 건너 뛰어 그 다음 명령문들을 수행하게 됩니다.
그러나 분모가 0 이 되는 상황, 즉 (3) 의 함수 코드에 나와 있는 'if' 문을 만족시키게 되면 (4) 에 나타나 있는 'throw' 키워드에 의해 제어가 예외 처리기인 (2) 의 'catch' 블록으로 넘어갑니다.
이 때, (4) 의 'throw' 키워드 뒤에 문자열이 나타나 있지요? (2) 의 'catch' 블록은 이것은 매개변수(const char *s) 로 받아서 일단 문자열을 출력합니다. 그리고 나서, 다른 한 쌍의 수를 입력하라고 하지요. 마지막으로, 'continue' 라는 명령문을 실행하여 'while' 루프의 나머지 코드를 건너 뛰고 다시 루프의 시작으로 점프하여 숫자를 입력 받고 이를 가지고 조화평균을 구하는 함수를 수행하는 일을 반복합니다.
자, 이제 예외 처리가 어떻게 이루어지는지 잘 이해하셨지요?
< 정리해봅시다 >
제 9 장 예외 처리를 모두 배우셨습니다. 앞서 배운 내용들을 다시 한번 점검해 보도록 하겠습니다.
처리는 유비무환 정신이 깃든 메커니즘입니다. 프로그램 수행 중 일어날 수 있는 오류에 대비해서, 이런 오류를 처리할 수 있는 코드를 미리 작성해 원활한 프로그램 수행을 돕는 것이지요.
장에서는 예외 처리 메커니즘을 제공하는 여러 프로그래밍 언어 가운데, C++ 의 예외 처리 메커니즘인 'try-catch' 문과 'throw' 키워드에 대하여 배웠습니다.
10 장 객체지향형 프로그래밍
두 음료 판매 회사가 있습니다. 두 회사가 생산하는 음료의 질은 똑같다고 가정해 봅시다. 그러나 두 회사의 마케팅 전략에는 약간의 차이가 있습니다. 한 회사는 회사 중심의 마케팅 전략을 고집하는 한편, 다른 한 회사는 소비자 중심의 마케팅 전략을 세워 음료 판매에 열을 올리고 있습니다. 과연 두 회사의 음료 판매량에는 어떤 변화가 있을까요? 위의 말대로라면 소비자 중심의 마케팅 전략을 구사하는 회사의 음료 판매량이 월등히 높겠지요.
프로그래밍 기법에서도 마찬가지로 똑같은 작업을 수행하는 프로그램을 짜더라도, 문제 해결의 방향을 어디서부터 잡고 시작하느냐에 따라 프로그램의 가치가 달라집니다.
이번 장에서는 기존 프로그래밍 기법의 개념을 바꾼 객체지향형 프로그래밍에 대하여 배워 보려고 합니다. 전통적인 프로그래밍 기법인 절차식 프로그래밍 기법과의 비교를 통하여 객체지향 프로그래밍 기법의 주요 특징과 구성 요소를 살펴 보고, 이를 이용한 예제 프로그램을 공부하도록 하겠습니다.
< 학습목표 >
- 객체지향형 프로그래밍에 대한 개념을 설명할 수 있습니다.
- 객체지향형 프로그래밍과 기존의 프로그래밍 기법과의 차이를 구분할 수 있습니다.
- 객체지향형 프로그래밍을 구성하는 구성 요소에 대한 개념을 이해하고 이러한 구성 요소가 프로그래밍 언어로 어떻게 표현되는지 말할 수 있습니다.
< 학습내용 >
- 객체지향형 프로그래밍 소개
- 객체지향형 프로그래밍의 구성 요소
- C++ 에서의 객체지향형 프로그래밍 부프로그램의 소개
1. 객체지향형 프로그램 소개
객체지향형 프로그래밍이란 계산에 의한 방법이 아니라 처리 방법과 자료가 하나의 묶음으로 구성되어 자료 추상화의 개념을 이용한 프로그래밍으로, 객체가 주체가 되어 객체들 사이의 메시지 전달 기법으로 문제를 해결합니다. 즉, 프로그램을 작성할 때, 원하는 작업을 수행할 함수나 프로시저 같은 부프로그램 위주의 문제 해결을 하는 것이 아니라, 프로그램에 필요한 자료(Data) 를 중심으로 문제 해결을 하는 것을 말합니다. 이 때, 사용되는 자료들을 논리적으로 표현한 것이 객체가 되는 것이지요. 객체에 대한 정확한 개념은 10.2 절에서 배우도록 하겠습니다.
객체지향형 프로그래밍의 개념은, 처음으로 클래스(Class) 라는 개념을 도입한 SIMULA67 에서 그 근원을 찾을 수 있습니다. 이후 최초의 그래픽 중심의 대화식 프로그래밍 환경을 갖춘 SMALLTALK 에서 그 개념을 확고히 하였습니다. 또한 C++, ADA95 등에서도 객체지향형 프로그래밍을 지원하고 있습니다.
객체지향형 프로그래밍 기법을 이용하여 소프트웨어를 만들면, 소프트웨어의 재사용성, 확장성 및 유지보수가 용이합니다. 그렇기 때문에 대형 프로그램 작성에 좋고, 프로그램의 읽기 쉬움(Readability) 이 좋습니다.
이와는 반대되는 개념으로, 앞서 언급한 바와 같이 작업을 수행할 함수나 프로시저 같은 부프로그램을 위주로 문제 해결을 하는 프로그래밍 기법을 절차식 프로그래밍이라고 합니다. PASCAL 이나 C, BASIC 등은 절차식 프로그래밍 언어에 속합니다.
좀더 이해를 돕고자 이야기 거리를 하나 곁들였습니다. 즐기면서 천천히 읽어 나가시기 바랍니다.
야구팀에 새로 입단한 여러분이 그 팀의 통계를 내 달라는 부탁을 받았다고 합시다. 여러분은 아마도 컴퓨터를 이용하여 해답을 구하려고 할 것이며, 만일 여러분이 절차식 프로그래밍에 익숙해 있다면 다음과 같은 생각을 하게 될 것입니다.
자, 나는 이름과 타석수, 안타수와 타율, 그리고 각 선수들의 중요한 기본 통계를 모두 입력해야지. 아무래도 컴퓨터를 이용해야 일이 쉬울 거야. 그래, 타율 같은 것은 금방 알 수 있을 테니까 말야. 그리고 결과를 보고서 형식으로 출력해야지. 가만, 이걸 어떻게 출력한다? 아무래도 함수를 이용해야겠지? 맞아! 메인 프로그램이 입력을 받는 프로그램을 호출한 후 계산을 하는 함수를 호출한 다음, 결과를 출력하는 함수를 호출하면 돼. 음, 그런데 다음 게임의 데이터를 받으면 어떻게 되지? 일을 처음부터 다시 시작할 수는 없잖아. 그래! 데이터 추가 작업과 갱신 작업 함수를 덧붙이는 거야! 그리고 아무래도 메인 프로그램에는 갱신, 추가, 입력, 출력, 계산 메뉴가 필요하겠군! 음, 그런데 이 데이터를 어떻게 나타낸다? 그래! 이런 경우에는 각 선수의 이름에 대한 문자열 배열과 타석수에 대한 배열, 그리고 안타수를 기억하는 배열을 이용하는 거야. 아냐! 그게 아니라 한 선수의 모든 정보를 한꺼번에 담는 구조체를 정의하고, 전체 팀에 대해서는 구조체의 배열을 설계하는 거야.
위의 이야기를 보시면 작업 수행에 필요한 함수에 우선 중점을 두게 되며 그 후 자료( 데이터) 를 표현할 방법을 찾고 있습니다. 그러나 위의 경우를 객체지향형 프로그래밍의 입장으로 바꾸어 표현한다면 다음과 같이 나타낼 수 있습니다. 여러분이 문제를 놓고 생각하는 방향은 우선 자료로 바뀌며 뿐만 아니라 이 자료를 어떻게 표현하는지, 그리고 어떻게 사용하는지로 바뀝니다.
자, 내가 무엇을 기억해야 하지? 선수들은 물론이겠지, 그래. 모든 선수들과 타율등을 나타내는 하나의 객체를 선언해야겠군. 음, 이것은 각 선수들의 이름과 그들의 통계를 나타내는 기본 객체가 될 수 있겠어. 그리고 이 객체를 다룰 메소드(Method) 들이 필요한데, 일단 객체에 기본적인 데이터를 제공하는 메소드가 필요해. 컴퓨터는 타율과 같은 데이터를 계산하는 것이니까, 계산을 하는 메소드를 추가하면 되겠군. 그리고, 프로그램은 이러한 계산들을 사용자가 신경 쓸 필요 없이 자동으로 해야 해. 그리고 데이터를 보여 주고, 갱신하는 작업을 하는 메소드도 필요하겠군. 사용자가 데이터를 다루는 메소드도 필요하겠어. 사용자는 데이터를 다룰 때, 초기화, 갱신, 보고서 작성 등을 하는 세 가지 방식을 가져야겠군. 이것이 사용자 인터페이스가 되는 셈이지.
위와 같이 여러분은 객체를 묘사하는 데 요구되는 자료와 이 자료로 처리해야 할 연산을 생각하며 사용자 입장에서 객체에 중점을 두게 됩니다. 이러한 인터페이스를 개발하고 난 후에는 인터페이스와 자료의 저장 형태를 구현하는 것에 대해 생각하게 되며, 마지막으로 새로운 설계를 위해서 이러한 것들을 하나로 모으게 됩니다.
2. C++ 에서의 객체지향형 프로그래밍
객체지향형 프로그래밍을 위한 구성 요소는 다음과 같습니다.
클래스 (Class)
- 하나 이상의 유사한 객체들을 묶어서 공통된 특성을 표현한 것을 말합니다.
- 자료 추상화를 지원하기 위한 기능으로, 절차형 언어에서의 자료형에 해당한다고 볼 수 있습니다. 이것을 추상 자료형이라고 하지요.
- 클래스는 여러 클래스들과 계층 구조를 가질 수 있으며 상위의 클래스를 수퍼 클래스(Super Class), 하위의 클래스를 서브 클래스(Sub Class) 라고 합니다.
객체 (Object)
- 프로그램 상에서 작동하는 주체를 객체라고 부릅니다.
- 절차식 프로그래밍에서의 자료와는 다르며, 객체지향 프로그래밍에서의 객체는 자료, 이 자료의 처리 방법 또는 이 둘을 합친 것 모두가 사용자에 의해 객체로 정의될 수 있습니다.
- 객체는 전용자료와 메소드( 처리 방법) 로 구성되며, 전용 자료는 객체의 물리적 구성 요소이며( 추상 자료형에서의 멤버 변수에 해당), 메소드는 객체의 행위( 추상 자료형에서의 멤버 함수에 해당) 입니다.
- 즉, 객체는 클래스를 이용하여 추상 자료형으로 표현될 수 있습니다.
인스턴스 (Instance)
- 특정 클래스로부터 만들어진 구체적인 객체를 말합니다. 다시 말해서, 클래스를 사용하여 추상 자료형을 정의한 후 이 추상 자료형으로 선언한 변수가 인스턴스가 되는 것입니다.
메소드 (Method)
- 객체의 구체적인 처리 연산을 정의한 것을 말합니다. 즉, 객체 속에 포함된 함수를 의미합니다.
- 하나의 객체에 하나 이상의 메소드를 정의할 수 있습니다.
상속 (Inheritance)
- 여러 개의 클래스가 계층 구조로 이루어져 있을 때에는 상위 클래스와 하위 클래스가 존재하게 되는데, 상위의 클래스로 갈수록 더 추상화된 형태이고, 하위로 갈수록 더 구체적인 클래스입니다.
- 이 때, 클래스의 계층 구조에서 하위의 클래스는 상위의 클래스의 속성을 그대로 물려 받을 수 있는데, 이것을 상속이라고 합니다. 즉, 하위 클래스는 상위 클래스의 모든 자료와 메소드를 그대로 사용할 수 있습니다.
C++ 에서는 객체들의 공통적인 특성을 정의하는 'class' 를 통해서 자료 추상화 기능을 제공합니다. 이 'class' 는 프로그래밍 언어에서 기본적으로 제공하는 자료형 이외에 사용자가 모델링하고자 하는 형 구조인 멤버(Member) 를 정의하고, 여기에 처리해야 할 연산들을 정의한 멤버 함수(Member Function) 을 정의해 줌으로써 사용자 정의형(User-Defined Type) 을 지원합니다. 또한 기본적인 연산자들의 의미를 사용자가 정의한 'class' 에 맞게 재정의할 수 있게 해주는 연산자 중복(Operator Overloading) 을 지원합니다. 예를 들어, 다음과 같은 코드
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/10/img/pl10_07_g01.gif" \* MERGEFORMATINET
에서 , '+' 연산자는 두 객체인 'amount1'과 'amout2'의 멤버 중 'all_cents'를 더하도록 재정의되고 있습니다 . 이러한 재정의에 의해 프로그램 상에서는 '+' 연산자를 다음과 같이 쓸 수 있습니다 .
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/10/img/pl10_07_g02.gif" \* MERGEFORMATINET
위의 코드는 '+' 연산자 정의에 의해 , 'cost'의 'all_cents'와 'tax'의 'all_cents'를 더해서 , 이 값을 'total'의 'all_cents'에 저장하게 됩니다 . 즉 ,
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/10/img/pl10_07_g03.gif" \* MERGEFORMATINET
과 같은 기능을 수행하는 것입니다. 그리고 상속 기능을 도입하여 완전한 객체지향형 프로그래밍 개념을 지원하며, 몇 개의 키워드를 이용해서 클래스의 멤버에 대한 접근을 제어함으로써 캡슐화를 가능하게 해줍니다. 원래 메인 프로그램에서는 'private' 으로 선언된 멤버 변수에 대한 접근이 허용되지 않지만, C++ 에서의 'friend' 키워드를 이용하면 클래스의 멤버 변수에 접근할 수 있습니다.
INCLUDEPICTURE "http://www.e-campus.co.kr/vmc/904/10/img/pl10_07_g04.gif" \* MERGEFORMATINET
원래 함수의 프로토타입은 프로그램 상단의 선언부에 기술하여야 합니다. 그렇지만 'friend' 함수로 사용하고 싶으면 함수의 프로토타입을 'class' 정의 블록 안에 기술하여 줍니다. 이렇게 하면 클래스의 멤버 함수가 아니더라도 그 클래스의 ' 친구' 자격을 얻어 클래스의 멤버 변수를 사용할 수 있는 것입니다.
이 강좌는 프로그래밍 언어에 대한 개괄적인 내용을 배우는 곳입니다. 따라서 여기서는 개념만 확실하게 기억하고, 좀더 자세한 프로그램 작성법은 C++ 프로그래밍 언어를 배우셔서 익히시기 바랍니다.
< 정리해봅시다 >
축하합니다. 제 10 장 객체지향형 프로그래밍을 모두 배움과 동시에 프로그래밍 언어 개론 과정을 모두 마치셨습니다. 이 장에서 배운 내용들을 다시 한번 점검해 보도록 하겠습니다.
프로그래밍은, 프로그램을 작성하기 위해 필요한 자료들과 그 자료들을 처리하는 연산들을 한데 모은 객체를 중심으로 문제를 해결해 나가는 프로그래밍 기법입니다.
프로그래밍을 위해 필요한 구성 요소로는 클래스, 객체, 인스턴스, 메소드, 상속이 있습니다.
C++ 언어를 이용해 객체지향 프로그램을 작성하는 방법을 개괄적으로 배웠습니다. C++ 에서 객체지향 프로그램을 작성하는 것은 8 장에서 배운 C++ 의 추상 자료형과 밀접한 관계가 있다는 것을 눈치 채셨을 것입니다. 결국 객체지향 프로그래밍 기법은 자료 추상화를 기반으로 하여 표현 가능하다는 것을 이해하셨으리라 생각됩니다.
< 연습문제 >
1. 객체지향형 프로그래밍과 절차식 프로그래밍 기법의 차이점에 대하여 설명해보세요.
객체지향형 프로그래밍이란 계산에 의한 방법이 아니라 처리 방법과 자료가 하나의 묶음으로 구성되어 자료 추상화의 개념을 이용한 프로그래밍으로, 객체가 주체가 되어 객체들 사이에 메시지 전달 기법으로 문제를 해결합니다. 이와는 반대로, 작업을 수행할 함수나 프로시저 같은 부프로그램을 위주로 문제 해결을 하는 프로그래밍 기법을 절차식 프로그래밍이라고 합니다.
2. 객체지향형 프로그래밍의 구성 요소에는 어떤 것들이 있는지 말해보세요.
클래스, 객체, 메소드, 인스턴스, 상속
less.. (본문 닫기) 


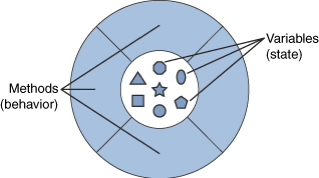
 invalid-file
invalid-file