to apply Particle filter to object tracking
3차원 파티클 필터를 이용한 물체(공) 추적 (contour tracking) 알고리즘 연습
- IplImage* cvRetrieveFrame(CvCapture* capture)
-
Gets the image grabbed with cvGrabFrame.
| Parameter: |
capture – video capturing structure. |
The function cvRetrieveFrame() returns the pointer to the image grabbed with the GrabFrame function. The returned image should not be released or modified by the user. In the event of an error, the return value may be NULL.
-
Canny edge detection
Canny edge detection in OpenCV image processing functions
- void cvCanny(const CvArr* image, CvArr* edges, double threshold1, double threshold2, int aperture_size=3)
-
Implements the Canny algorithm for edge detection.
| Parameters: |
- image – Single-channel input image
- edges – Single-channel image to store the edges found by the function
- threshold1 – The first threshold
- threshold2 – The second threshold
- aperture_size – Aperture parameter for the Sobel operator (see cvSobel())
|
The function cvCanny() finds the edges on the input image image and marks them in the output image edges using the Canny algorithm. The smallest value between threshold1 and threshold2 is used for edge linking, the largest value is used to find the initial segments of strong edges.
-
source cod...ing
// 3-D Particle filter algorithm + Computer Vision exercise
// : object tracking - contour tracking
// lym, VIP Lab, Sogang Univ.
// 2009-11-23
// ref. Probabilistic Robotics: 98p
#include <OpenCV/OpenCV.h> // matrix operations & Canny edge detection
#include <iostream>
#include <cstdlib> // RAND_MAX
#include <ctime> // time as a random seed
#include <cmath>
#include <algorithm>
using namespace std;
#define PI 3.14159265
#define N 100 //number of particles
#define D 3 // dimension of the state
// uniform random number generator
double uniform_random(void) {
return (double) rand() / (double) RAND_MAX;
}
// Gaussian random number generator
double gaussian_random(void) {
static int next_gaussian = 0;
static double saved_gaussian_value;
double fac, rsq, v1, v2;
if(next_gaussian == 0) {
do {
v1 = 2.0 * uniform_random() - 1.0;
v2 = 2.0 * uniform_random() - 1.0;
rsq = v1 * v1 + v2 * v2;
}
while(rsq >= 1.0 || rsq == 0.0);
fac = sqrt(-2.0 * log(rsq) / rsq);
saved_gaussian_value = v1 * fac;
next_gaussian = 1;
return v2 * fac;
}
else {
next_gaussian = 0;
return saved_gaussian_value;
}
}
double normal_distribution(double mean, double standardDeviation, double state) {
double variance = standardDeviation * standardDeviation;
return exp(-0.5 * (state - mean) * (state - mean) / variance ) / sqrt(2 * PI * variance);
}
////////////////////////////////////////////////////////////////////////////
// distance between measurement and prediction
double distance(CvMat* measurement, CvMat* prediction)
{
double distance2 = 0;
double differance = 0;
for (int u = 0; u < 3; u++)
{
differance = cvmGet(measurement,u,0) - cvmGet(prediction,u,0);
distance2 += differance * differance;
}
return sqrt(distance2);
}
double distanceEuclidean(CvPoint2D64f a, CvPoint2D64f b)
{
double d2 = (a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y);
return sqrt(d2);
}
// likelihood based on multivariative normal distribution (ref. 15p eqn(2.4))
double likelihood(CvMat *mean, CvMat *covariance, CvMat *sample) {
CvMat* diff = cvCreateMat(3, 1, CV_64FC1);
cvSub(sample, mean, diff); // sample - mean -> diff
CvMat* diff_t = cvCreateMat(1, 3, CV_64FC1);
cvTranspose(diff, diff_t); // transpose(diff) -> diff_t
CvMat* cov_inv = cvCreateMat(3, 3, CV_64FC1);
cvInvert(covariance, cov_inv); // transpose(covariance) -> cov_inv
CvMat* tmp = cvCreateMat(3, 1, CV_64FC1);
CvMat* dist = cvCreateMat(1, 1, CV_64FC1);
cvMatMul(cov_inv, diff, tmp); // cov_inv * diff -> tmp
cvMatMul(diff_t, tmp, dist); // diff_t * tmp -> dist
double likeliness = exp( -0.5 * cvmGet(dist, 0, 0) );
double bound = 0.0000001;
if ( likeliness < bound )
{
likeliness = bound;
}
return likeliness;
// return exp( -0.5 * cvmGet(dist, 0, 0) );
// return max(0.0000001, exp(-0.5 * cvmGet(dist, 0, 0)));
}
// likelihood based on normal distribution (ref. 14p eqn(2.3))
double likelihood(double distance, double standardDeviation) {
double variance = standardDeviation * standardDeviation;
return exp(-0.5 * distance*distance / variance ) / sqrt(2 * PI * variance);
}
int main (int argc, char * const argv[]) {
srand(time(NULL));
IplImage *iplOriginalColor; // image to be captured
IplImage *iplOriginalGrey; // grey-scale image of "iplOriginalColor"
IplImage *iplEdge; // image detected by Canny edge algorithm
IplImage *iplImg; // resulting image to show tracking process
IplImage *iplEdgeClone;
int hours, minutes, seconds;
double frame_rate, Codec, frame_count, duration;
char fnVideo[200], titleOriginal[200], titleEdge[200], titleResult[200];
sprintf(titleOriginal, "original");
sprintf(titleEdge, "Edges by Canny detector");
// sprintf(fnVideo, "E:/AVCHD/BDMV/STREAM/00092.avi");
sprintf(fnVideo, "/Users/lym/Documents/VIP/2009/Nov/volleyBall.mov");
sprintf(titleResult, "3D Particle filter for contour tracking");
CvCapture *capture = cvCaptureFromAVI(fnVideo);
// stop the process if capture is failed
if(!capture) { printf("Can NOT read the movie file\n"); return -1; }
frame_rate = cvGetCaptureProperty(capture, CV_CAP_PROP_FPS);
// Codec = cvGetCaptureProperty( capture, CV_CAP_PROP_FOURCC );
frame_count = cvGetCaptureProperty( capture, CV_CAP_PROP_FRAME_COUNT);
duration = frame_count/frame_rate;
hours = duration/3600;
minutes = (duration-hours*3600)/60;
seconds = duration-hours*3600-minutes*60;
// stop the process if grabbing is failed
// if(cvGrabFrame(capture) == 0) { printf("Can NOT grab a frame\n"); return -1; }
cvSetCaptureProperty(capture, CV_CAP_PROP_POS_FRAMES, 0); // go to frame #0
iplOriginalColor = cvRetrieveFrame(capture);
iplOriginalGrey = cvCreateImage(cvGetSize(iplOriginalColor), 8, 1);
iplEdge = cvCloneImage(iplOriginalGrey);
iplEdgeClone = cvCreateImage(cvSize(iplOriginalColor->width, iplOriginalColor->height), 8, 3);
iplImg = cvCreateImage(cvSize(iplOriginalColor->width, iplOriginalColor->height), 8, 3);
int width = iplOriginalColor->width;
int height = iplOriginalColor->height;
cvNamedWindow(titleOriginal);
cvNamedWindow(titleEdge);
cout << "image width : height = " << width << " " << height << endl;
cout << "# of frames = " << frame_count << endl;
cout << "capture finished" << endl;
// set the system
// set the process noise
// covariance of Gaussian noise to control
CvMat* transition_noise = cvCreateMat(D, D, CV_64FC1);
// assume the transition noise
for (int row = 0; row < D; row++)
{
for (int col = 0; col < D; col++)
{
cvmSet(transition_noise, row, col, 0.0);
}
}
cvmSet(transition_noise, 0, 0, 3.0);
cvmSet(transition_noise, 1, 1, 3.0);
cvmSet(transition_noise, 2, 2, 0.3);
// set the measurement noise
/*
// covariance of Gaussian noise to measurement
CvMat* measurement_noise = cvCreateMat(D, D, CV_64FC1);
// initialize the measurement noise
for (int row = 0; row < D; row++)
{
for (int col = 0; col < D; col++)
{
cvmSet(measurement_noise, row, col, 0.0);
}
}
cvmSet(measurement_noise, 0, 0, 5.0);
cvmSet(measurement_noise, 1, 1, 5.0);
cvmSet(measurement_noise, 2, 2, 5.0);
*/
double measurement_noise = 2.0; // standrad deviation of Gaussian noise to measurement
CvMat* state = cvCreateMat(D, 1, CV_64FC1); // state of the system to be estimated
// CvMat* measurement = cvCreateMat(2, 1, CV_64FC1); // measurement of states
// declare particles
CvMat* pb [N]; // estimated particles
CvMat* pp [N]; // predicted particles
CvMat* pu [N]; // temporary variables to update a particle
CvMat* v[N]; // estimated velocity of each particle
CvMat* vu[N]; // temporary varialbe to update the velocity
double w[N]; // weight of each particle
for (int n = 0; n < N; n++)
{
pb[n] = cvCreateMat(D, 1, CV_64FC1);
pp[n] = cvCreateMat(D, 1, CV_64FC1);
pu[n] = cvCreateMat(D, 1, CV_64FC1);
v[n] = cvCreateMat(D, 1, CV_64FC1);
vu[n] = cvCreateMat(D, 1, CV_64FC1);
}
// initialize the state and particles
for (int n = 0; n < N; n++)
{
cvmSet(state, 0, 0, 258.0); // center-x
cvmSet(state, 1, 0, 406.0); // center-y
cvmSet(state, 2, 0, 38.0); // radius
// cvmSet(state, 0, 0, 300.0); // center-x
// cvmSet(state, 1, 0, 300.0); // center-y
// cvmSet(state, 2, 0, 38.0); // radius
cvmSet(pb[n], 0, 0, cvmGet(state,0,0)); // center-x
cvmSet(pb[n], 1, 0, cvmGet(state,1,0)); // center-y
cvmSet(pb[n], 2, 0, cvmGet(state,2,0)); // radius
cvmSet(v[n], 0, 0, 2 * uniform_random()); // center-x
cvmSet(v[n], 1, 0, 2 * uniform_random()); // center-y
cvmSet(v[n], 2, 0, 0.1 * uniform_random()); // radius
w[n] = (double) 1 / (double) N; // equally weighted particle
}
// initialize the image window
cvZero(iplImg);
cvNamedWindow(titleResult);
cout << "start filtering... " << endl << endl;
float aperture = 3, thresLow = 50, thresHigh = 110;
// float aperture = 3, thresLow = 80, thresHigh = 110;
// for each frame
int frameNo = 0;
while(frameNo < frame_count && cvGrabFrame(capture)) {
// retrieve color frame from the movie "capture"
iplOriginalColor = cvRetrieveFrame(capture);
// convert color pixel values of "iplOriginalColor" to grey scales of "iplOriginalGrey"
cvCvtColor(iplOriginalColor, iplOriginalGrey, CV_RGB2GRAY);
// extract edges with Canny detector from "iplOriginalGrey" to save the results in the image "iplEdge"
cvCanny(iplOriginalGrey, iplEdge, thresLow, thresHigh, aperture);
cvCvtColor(iplEdge, iplEdgeClone, CV_GRAY2BGR);
cvShowImage(titleOriginal, iplOriginalColor);
cvShowImage(titleEdge, iplEdge);
// cvZero(iplImg);
cout << "frame # " << frameNo << endl;
double like[N]; // likelihood between measurement and prediction
double like_sum = 0; // sum of likelihoods
for (int n = 0; n < N; n++) // for "N" particles
{
// predict
double prediction;
for (int row = 0; row < D; row++)
{
prediction = cvmGet(pb[n],row,0) + cvmGet(v[n],row,0)
+ cvmGet(transition_noise,row,row) * gaussian_random();
cvmSet(pp[n], row, 0, prediction);
}
if ( cvmGet(pp[n],2,0) < 2) { cvmSet(pp[n],2,0,0.0); }
// cvLine(iplImg, cvPoint(cvRound(cvmGet(pp[n],0,0)), cvRound(cvmGet(pp[n],1,0))),
// cvPoint(cvRound(cvmGet(pb[n],0,0)), cvRound(cvmGet(pb[n],1,0))), CV_RGB(100,100,0), 1);
cvCircle(iplEdgeClone, cvPoint(cvRound(cvmGet(pp[n],0,0)), cvRound(cvmGet(pp[n],1,0))), cvRound(cvmGet(pp[n],2,0)), CV_RGB(255, 255, 0));
// cvCircle(iplImg, cvPoint(iplImg->width *0.5, iplImg->height * 0.5), 100, CV_RGB(255, 255, 0), -1);
// cvSaveImage("a.bmp", iplImg);
double cX = cvmGet(pp[n], 0, 0); // predicted center-y of the object
double cY = cvmGet(pp[n], 1, 0); // predicted center-x of the object
double cR = cvmGet(pp[n], 2, 0); // predicted radius of the object
if ( cR < 0 ) { cR = 0; }
// measure
// search measurements
CvPoint2D64f direction [8]; // 8 searching directions
// define 8 starting points in each direction
direction[0].x = cX + cR; direction[0].y = cY; // East
direction[2].x = cX; direction[2].y = cY - cR; // North
direction[4].x = cX - cR; direction[4].y = cY; // West
direction[6].x = cX; direction[6].y = cY + cR; // South
int cD = cvRound( cR/sqrt(2.0) );
direction[1].x = cX + cD; direction[1].y = cY - cD; // NE
direction[3].x = cX - cD; direction[3].y = cY - cD; // NW
direction[5].x = cX - cD; direction[5].y = cY + cD; // SW
direction[7].x = cX + cD; direction[7].y = cY + cD; // SE
CvPoint2D64f search [8]; // searched point in each direction
double scale = 0.4;
double scope [8]; // scope of searching
for ( int i = 0; i < 8; i++ )
{
// scope[2*i] = cR * scale;
// scope[2*i+1] = cD * scale;
scope[i] = 6.0;
}
CvPoint d[8];
d[0].x = 1; d[0].y = 0; // E
d[1].x = 1; d[1].y = -1; // NE
d[2].x = 0; d[2].y = 1; // N
d[3].x = 1; d[3].y = 1; // NW
d[4].x = 1; d[4].y = 0; // W
d[5].x = 1; d[5].y = -1; // SW
d[6].x = 0; d[6].y = 1; // S
d[7].x = 1; d[7].y = 1; // SE
int count = 0; // number of measurements
double dist_sum = 0;
for (int i = 0; i < 8; i++) // for 8 directions
{
double dist = scope[i] * 1.5;
for ( int range = 0; range < scope[i]; range++ )
{
int flag = 0;
for (int turn = -1; turn <= 1; turn += 2) // reverse the searching direction
{
search[i].x = direction[i].x + turn * range * d[i].x;
search[i].y = direction[i].y + turn * range * d[i].y;
// cvCircle(iplImg, cvPoint(cvRound(search[i].x), cvRound(search[i].y)), 2, CV_RGB(0, 255, 0), -1);
// cvShowImage(titleResult, iplImg);
// cvWaitKey(100);
// detect measurements
// CvScalar s = cvGet2D(iplEdge, cvRound(search[i].y), cvRound(search[i].x));
unsigned char s = CV_IMAGE_ELEM(iplEdge, unsigned char, cvRound(search[i].y), cvRound(search[i].x));
// if ( s.val[0] > 200 && s.val[1] > 200 && s.val[2] > 200 ) // bgr color
if (s > 250) // bgr color
{ // when the pixel value is white, that means a measurement is detected
flag = 1;
count++;
// cvCircle(iplEdgeClone, cvPoint(cvRound(search[i].x), cvRound(search[i].y)), 3, CV_RGB(200, 0, 255));
// cvShowImage("3D Particle filter", iplEdgeClone);
// cvWaitKey(1);
/* // get measurement
cvmSet(measurement, 0, 0, search[i].x);
cvmSet(measurement, 1, 0, search[i].y);
double dist = distance(measurement, pp[n]);
*/ // evaluate the difference between predictions of the particle and measurements
dist = distanceEuclidean(search[i], direction[i]);
break; // break for "turn"
} // end if
} // for turn
if ( flag == 1 )
{ break; } // break for "range"
} // for range
dist_sum += dist; // for all searching directions of one particle
} // for i direction
double dist_avg; // average distance of measurements from the one particle "n"
// cout << "count = " << count << endl;
dist_avg = dist_sum / 8;
// cout << "dist_avg = " << dist_avg << endl;
// estimate likelihood with "dist_avg"
like[n] = likelihood(dist_avg, measurement_noise);
// cout << "likelihood of particle-#" << n << " = " << like[n] << endl;
like_sum += like[n];
} // for n particle
// cout << "sum of likelihoods of N particles = " << like_sum << endl;
// estimate states
double state_x = 0.0;
double state_y = 0.0;
double state_r = 0.0;
// estimate the state with predicted particles
for (int n = 0; n < N; n++) // for "N" particles
{
w[n] = like[n] / like_sum; // update normalized weights of particles
// cout << "w" << n << "= " << w[n] << " ";
state_x += w[n] * cvmGet(pp[n], 0, 0); // center-x of the object
state_y += w[n] * cvmGet(pp[n], 1, 0); // center-y of the object
state_r += w[n] * cvmGet(pp[n], 2, 0); // radius of the object
}
if (state_r < 0) { state_r = 0; }
cvmSet(state, 0, 0, state_x);
cvmSet(state, 1, 0, state_y);
cvmSet(state, 2, 0, state_r);
cout << endl << "* * * * * *" << endl;
cout << "estimation: (x,y,r) = " << cvmGet(state,0,0) << ", " << cvmGet(state,1,0)
<< ", " << cvmGet(state,2,0) << endl;
cvCircle(iplEdgeClone, cvPoint(cvRound(cvmGet(state,0,0)), cvRound(cvmGet(state,1,0)) ),
cvRound(cvmGet(state,2,0)), CV_RGB(255, 0, 0), 1);
cvShowImage(titleResult, iplEdgeClone);
cvWaitKey(1);
// update particles
cout << endl << "updating particles" << endl;
double a[N]; // portion between particles
// define integrated portions of each particles; 0 < a[0] < a[1] < a[2] = 1
a[0] = w[0];
for (int n = 1; n < N; n++)
{
a[n] = a[n - 1] + w[n];
// cout << "a" << n << "= " << a[n] << " ";
}
// cout << "a" << N << "= " << a[N] << " " << endl;
for (int n = 0; n < N; n++)
{
// select a particle from the distribution
int pselected;
for (int k = 0; k < N; k++)
{
if ( uniform_random() < a[k] )
{
pselected = k;
break;
}
}
// cout << "p " << n << " => " << pselected << " ";
// retain the selection
for (int row = 0; row < D; row++)
{
cvmSet(pu[n], row, 0, cvmGet(pp[pselected],row,0));
cvSub(pp[pselected], pb[pselected], vu[n]); // pp - pb -> vu
}
}
// updated each particle and its velocity
for (int n = 0; n < N; n++)
{
for (int row = 0; row < D; row++)
{
cvmSet(pb[n], row, 0, cvmGet(pu[n],row,0));
cvmSet(v[n], row , 0, cvmGet(vu[n],row,0));
}
}
cout << endl << endl ;
// cvShowImage(titleResult, iplImg);
// cvWaitKey(1000);
cvWaitKey(1);
frameNo++;
}
cvWaitKey();
return 0;
}

 UndelayedBOSLAM.pdf
UndelayedBOSLAM.pdf









 VideoSource_OSX.cc
VideoSource_OSX.cc



 Ehnes, J., Hirota, K., and Hirose, M. 2004.
Ehnes, J., Hirota, K., and Hirose, M. 2004.  lights.txt
lights.txt


 outcomes is defined by
outcomes is defined by
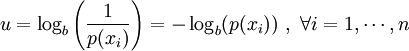
 , with
, with  being the average operator, is obtained by
being the average operator, is obtained by
